尝试直接访问API
在爬取数据时,常见的情况是网页通过API端点异步请求数据。以下是一个最简示例:
<body>
<script>
fetch("https://jsonplaceholder.typicode.com/posts/1")
.then(res => {
if (!res.ok) throw Error(res.status);
return res.json();
})
.then(data => {
document.body.innerText = data.title;
})
.catch(err => console.error(err))
;
</script>
</body>
在许多情况下,API将受到CORS或访问令牌的保护,或者受到限制性速率限制,但在其他情况下,它是公开可访问的,您可以完全绕过网站。对于CORS问题,您可以尝试使用
cors-anywhere。
一般的步骤是使用浏览器的开发人员工具网络选项卡搜索页面发出的请求,以获取您想要抓取的数据的关键字/子字符串。通常,您会看到一个没有保护的API请求端点,其中包含一个JSON有效负载,您可以直接使用urllib或requests模块访问。这就是上面可运行片段的情况,您可以用它来练习。点击“运行片段”后,这是我在网络选项卡中找到端点的方法:
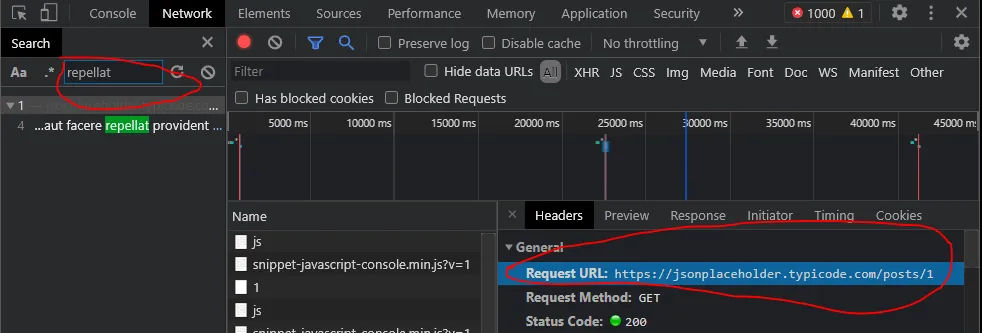
这个例子是人为构造的;从静态标记中看,端点URL可能不明显,因为它可能会被动态组装、压缩并埋藏在其他请求和端点之下。网络请求还将显示任何相关的请求有效载荷细节,如您可能需要的访问令牌。
获取端点URL和相关详细信息后,使用标准的HTTP库在Python中构建请求并请求数据:
>>> import requests
>>> res = requests.get("https://jsonplaceholder.typicode.com/posts/1")
>>> data = res.json()
>>> data["title"]
'sunt aut facere repellat provident occaecati excepturi optio reprehenderit'
当你可以这样做时,这通常比使用Selenium、Playwright-Python、Scrapy或任何流行的网络爬虫库更容易、更快速、更可靠,以便获取页面数据。如果你不幸的话,数据没有通过API请求以良好的格式返回,那么它可能是原始浏览器负载中的一部分,位于
<script>标签中,可能是JSON字符串或JS对象。例如:
<body>
<script>
var someHardcodedData = {
userId: 1,
id: 1,
title: 'sunt aut facere repellat provident occaecati excepturi optio reprehenderit',
body: 'quia et suscipit\nsuscipit recusandae con sequuntur expedita et cum\nreprehenderit molestiae ut ut quas totam\nnostrum rerum est autem sunt rem eveniet architecto'
};
document.body.textContent = someHardcodedData.title;
</script>
</body>
获得这些数据没有一种万能的方法。基本技术是使用BeautifulSoup访问<script>标签文本,然后应用正则表达式或解析来提取对象结构、JSON字符串或任何可能的数据格式。以下是一个概念验证,介绍了上面示例结构的实现:
import json
import re
from bs4 import BeautifulSoup
text = """
<body>
<script>
var someHardcodedData = {
userId: 1,
id: 1,
title: 'sunt aut facere repellat provident occaecati excepturi optio reprehenderit',
body: 'quia et suscipit\nsuscipit recusandae con sequuntur expedita et cum\nreprehenderit molestiae ut ut quas totam\nnostrum rerum est autem sunt rem eveniet architecto'
};
document.body.textContent = someHardcodedData.title;
</script>
</body>
"""
soup = BeautifulSoup(text, "lxml")
script_text = str(soup.select_one("script"))
pattern = r"title: '(.*?)'"
print(re.search(pattern, script_text, re.S).group(1))
查看以下资源,以解析不完全符合JSON格式的JS对象:
这里有一些额外的案例研究/概念证明,展示了如何使用API绕过网络爬虫的限制:
如果所有其他方法都失败了,请尝试此主题中列出的许多动态爬取库之一。