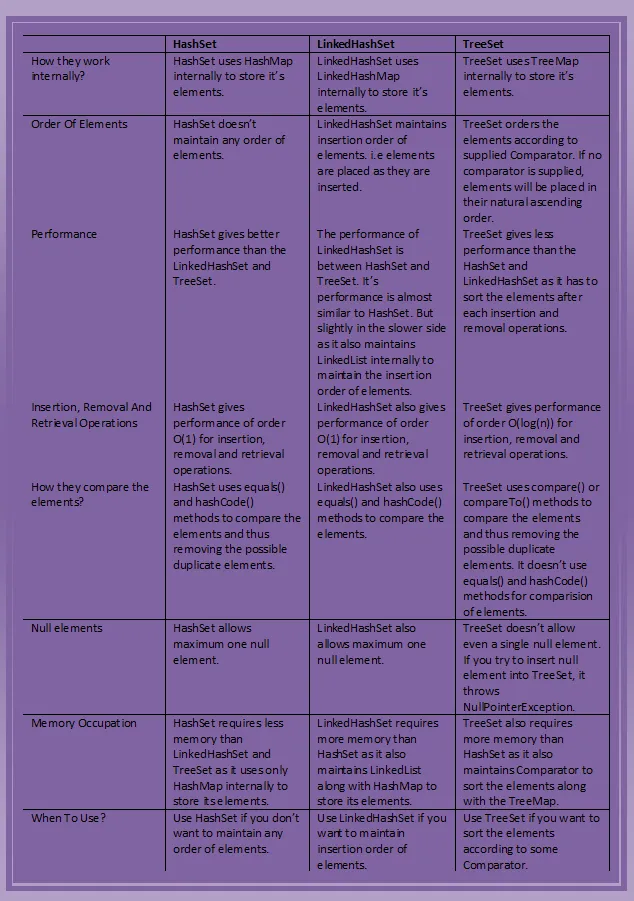
我正在学习Java核心的精华——Collections。我想知道在HashSet、TreeSet和LinkedHashSet中添加重复元素时内部会发生什么。
是否替换条目,忽略还是抛出异常并终止程序。还有一个子问题是,其中哪一个对于所有操作具有相同或平均时间复杂度
非常感谢您的回复。
我正在学习Java核心的精华——Collections。我想知道在HashSet、TreeSet和LinkedHashSet中添加重复元素时内部会发生什么。
是否替换条目,忽略还是抛出异常并终止程序。还有一个子问题是,其中哪一个对于所有操作具有相同或平均时间复杂度
非常感谢您的回复。
TreeSet cities
Exception in thread "main" java.lang.NullPointerException
at java.lang.String.compareTo(String.java:1167)
at java.lang.String.compareTo(String.java:92)
at java.util.TreeMap.put(TreeMap.java:545)
at java.util.TreeSet.add(TreeSet.java:238)
HashSet和LinkedHashSet在Java中使用equals()方法进行比较,而TreeSet使用compareTo()方法来维护排序。因此,在Java中,compareTo()应该与equals保持一致。如果没有这样做,就会破坏Set接口的普遍约定,即它可能允许重复项。
您可以使用以下链接查看内部实现:http://grepcode.com/file/repository.grepcode.com/java/root/jdk/openjdk/6-b14/java/util/HashSet.java#HashSet.add%28java.lang.Object%29
From the source code
Hashset hases Hashmap to store the data and LinkedHashSet extends Hashset and hence uses same add method of Hashset But TreeSet uses NavigableMap to store the data
new TreeSet<>(Comparator.nullFirst(Comparator.naturalOrder)),它将正常工作。 - kapexnew TreeSet<>(Comparator.nullFirst(Comparator.naturalOrder)),它可以正常工作。 - kapex我没有找到太多关于它们之间差异的硬数据,所以我对这3种情况进行了基准测试。
看起来,在添加时 HashSet 比 TreeSet 快约4倍(在某些情况下,这可能会根据您的数据的确切特征而有所不同)。
# Run complete. Total time: 00:22:47
Benchmark Mode Cnt Score Error Units
DeduplicationWithSetsBenchmark.deduplicateWithHashSet thrpt 200 7.734 ▒ 0.133 ops/s
DeduplicationWithSetsBenchmark.deduplicateWithLinkedHashSet thrpt 200 7.100 ▒ 0.171 ops/s
DeduplicationWithSetsBenchmark.deduplicateWithTreeSet thrpt 200 1.983 ▒ 0.032 ops/s
以下是基准测试代码:
package my.app;
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.Comparator;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Random;
import java.util.Set;
import java.util.TreeSet;
public class DeduplicationWithSetsBenchmark {
static Item[] inputData = makeInputData();
@Benchmark
public int deduplicateWithHashSet() {
return deduplicate(new HashSet<>());
}
@Benchmark
public int deduplicateWithLinkedHashSet() {
return deduplicate(new LinkedHashSet<>());
}
@Benchmark
public int deduplicateWithTreeSet() {
return deduplicate(new TreeSet<>(Item.comparator()));
}
private int deduplicate(Set<Item> set) {
for (Item i : inputData) {
set.add(i);
}
return set.size();
}
public static void main(String[] args) throws RunnerException {
// Verify that all 3 methods give the same answers:
DeduplicationWithSetsBenchmark x = new DeduplicationWithSetsBenchmark();
int count = x.deduplicateWithHashSet();
assert(count < inputData.length);
assert(count == x.deduplicateWithLinkedHashSet());
assert(count == x.deduplicateWithTreeSet());
Options opt = new OptionsBuilder()
.include(DeduplicationWithSetsBenchmark.class.getSimpleName())
.forks(1)
.build();
new Runner(opt).run();
}
private static Item[] makeInputData() {
int count = 1000000;
Item[] acc = new Item[count];
Random rnd = new Random();
for (int i=0; i<count; i++) {
Item item = new Item();
// We are looking to include a few collisions, so restrict the space of the values
item.name = "the item name " + rnd.nextInt(100);
item.id = rnd.nextInt(100);
acc[i] = item;
}
return acc;
}
private static class Item {
public String name;
public int id;
public String getName() {
return name;
}
public int getId() {
return id;
}
@Override
public boolean equals(Object obj) {
Item other = (Item) obj;
return name.equals(other.name) && id == other.id;
}
@Override
public int hashCode() {
return name.hashCode() * 13 + id;
}
static Comparator<Item> comparator() {
return Comparator.comparing(Item::getName, Comparator.naturalOrder())
.thenComparing(Item::getId, Comparator.naturalOrder());
}
}
}
简而言之:这些集合会忽略重复的值。
我还没有看到对于问题中加粗部分的完整回答,重复的值到底会发生什么?它会覆盖旧对象还是忽略新对象?考虑一个对象的例子,其中一个字段确定相等性,但有可能存在额外的数据变化:
public class MyData implements Comparable {
public final Integer valueDeterminingEquality;
public final String extraData;
public MyData(Integer valueDeterminingEquality, String extraData) {
this.valueDeterminingEquality = valueDeterminingEquality;
this.extraData = extraData;
}
@Override
public boolean equals(Object o) {
return valueDeterminingEquality.equals(((MyData) o).valueDeterminingEquality);
}
@Override
public int hashCode() {
return valueDeterminingEquality.hashCode();
}
@Override
public int compareTo(Object o) {
return valueDeterminingEquality.compareTo(((MyData)o).valueDeterminingEquality);
}
}
这个单元测试表明所有三个集合都会忽略重复的值:
import org.junit.Test;
import org.junit.runner.RunWith;
import org.junit.runners.Parameterized;
import java.util.*;
import static org.hamcrest.CoreMatchers.is;
import static org.hamcrest.MatcherAssert.assertThat;
@RunWith(Parameterized.class)
public class SetRepeatedItemTest {
private final Set<MyData> testSet;
public SetRepeatedItemTest(Set<MyData> testSet) {
this.testSet = testSet;
}
@Parameterized.Parameters
public static Collection<Object[]> data() {
return Arrays.asList(new Object[][] {
{ new TreeSet() }, { new HashSet() }, { new LinkedHashSet()}
});
}
@Test
public void testTreeSet() throws Exception {
testSet.add(new MyData(1, "object1"));
testSet.add(new MyData(1, "object2"));
assertThat(testSet.size(), is(1));
assertThat(testSet.iterator().next().extraData, is("object1"));
}
}
我也研究了TreeSet的实现,我们知道它使用了TreeMap... 在TreeSet.java文件中:
public boolean add(E var1) {
return this.m.put(var1, PRESENT) == null;
}
不要展示TreeMap的整个put方法,这里是相关的搜索循环:
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
所以如果cmp == 0,也就是说我们找到了一个重复的条目,则提前返回而不是在循环结束时添加一个子节点。调用setValue实际上并没有做任何事情,因为TreeSet在这里使用虚拟数据作为值,重要的是键不会改变。如果你研究HashMap,你会发现它也有相同的行为。