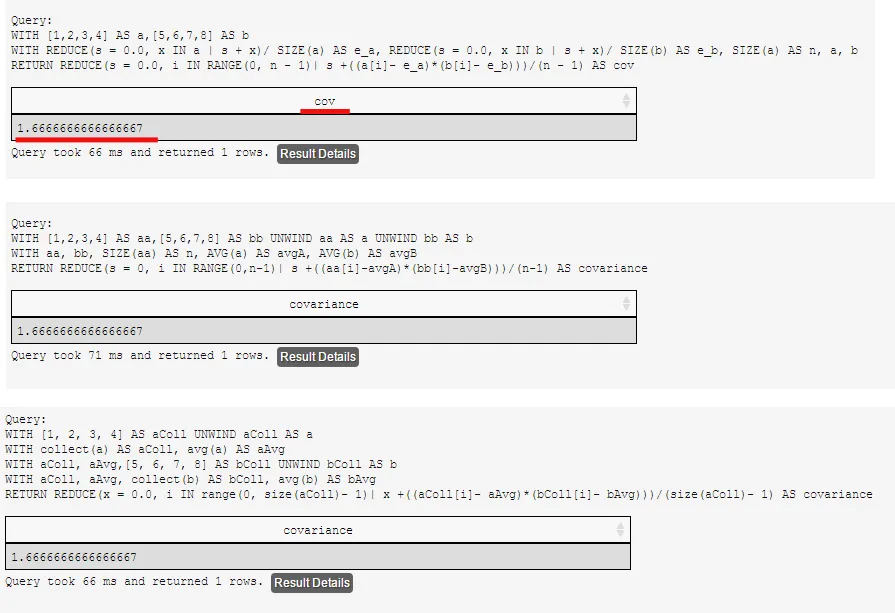
cybersam的答案完全没问题,但如果你想避免双重UNWIND导致的n^2笛卡尔积,你可以尝试以下方法:
WITH [1,2,3,4] AS a, [5,6,7,8] AS b
WITH REDUCE(s = 0.0, x IN a | s + x) / SIZE(a) AS e_a,
REDUCE(s = 0.0, x IN b | s + x) / SIZE(b) AS e_b,
SIZE(a) AS n, a, b
RETURN REDUCE(s = 0.0, i IN RANGE(0, n - 1) | s + ((a[i] - e_a) * (b[i] - e_b))) / (n - 1) AS cov;
编辑:
不是在指责任何人,但是让我更详细地解释一下为什么你要避免https://dev59.com/NpLea4cB1Zd3GeqP01a2#34423783中的双重UNWIND。就像我下面说的那样,在Cypher中对长度为n的k个集合进行UNWIND操作会导致n^k行结果。所以我们来看两个长度为3的集合,你想计算它们之间的协方差。
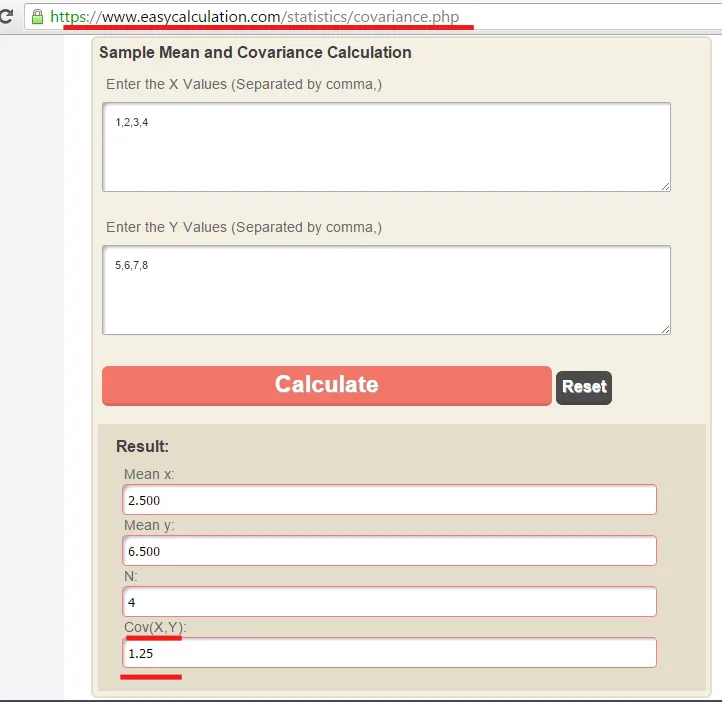
> WITH [1,2,3] AS a, [4,5,6] AS b
UNWIND a AS aa
UNWIND b AS bb
RETURN aa, bb;
| aa | bb
1 | 1 | 4
2 | 1 | 5
3 | 1 | 6
4 | 2 | 4
5 | 2 | 5
6 | 2 | 6
7 | 3 | 4
8 | 3 | 5
9 | 3 | 6
现在我们有
n^k = 3^2 = 9行。此时,对这些标识符取平均值意味着我们要对9个值取平均值。
> WITH [1,2,3] AS a, [4,5,6] AS b
UNWIND a AS aa
UNWIND b AS bb
RETURN AVG(aa), AVG(bb);
| AVG(aa) | AVG(bb)
1 | 2.0 | 5.0
此外,正如我在下面所说的,这不会影响答案,因为重复数字的向量的平均值总是相同的。例如,{1,2,3} 的平均值等于 {1,2,3,1,2,3} 的平均值。对于小的
n 值,这可能无关紧要,但当你开始获取较大的
n 值时,你将开始看到性能下降。
假设你有两个长度为 1000 的向量。使用双倍展开计算每个向量的平均值:
> WITH RANGE(0, 1000) AS a, RANGE(1000, 2000) AS b
UNWIND a AS aa
UNWIND b AS bb
RETURN AVG(aa), AVG(bb);
| AVG(aa) | AVG(bb)
1 | 500.0 | 1500.0
714毫秒
与使用REDUCE相比明显较慢:
> WITH RANGE(0, 1000) AS a, RANGE(1000, 2000) AS b
RETURN REDUCE(s = 0.0, x IN a | s + x) / SIZE(a) AS e_a,
REDUCE(s = 0.0, x IN b | s + x) / SIZE(b) AS e_b;
| e_a | e_b
1 | 500.0 | 1500.0
4毫秒
为了将其整合在一起,我将比较两个查询在长度为1000的向量上的完整性:
> WITH RANGE(0, 1000) AS aa, RANGE(1000, 2000) AS bb
UNWIND aa AS a
UNWIND bb AS b
WITH aa, bb, SIZE(aa) AS n, AVG(a) AS avgA, AVG(b) AS avgB
RETURN REDUCE(s = 0, i IN RANGE(0,n-1)| s +((aa[i]-avgA)*(bb[i]-avgB)))/(n-1) AS
covariance;
| covariance
1 | 83583.5
9105毫秒
> WITH RANGE(0, 1000) AS a, RANGE(1000, 2000) AS b
WITH REDUCE(s = 0.0, x IN a | s + x) / SIZE(a) AS e_a,
REDUCE(s = 0.0, x IN b | s + x) / SIZE(b) AS e_b,
SIZE(a) AS n, a, b
RETURN REDUCE(s = 0.0, i IN RANGE(0, n - 1) | s + ((a[i] - e_a) * (b[i
] - e_b))) / (n - 1) AS cov;
| cov
1 | 83583.5
33 毫秒
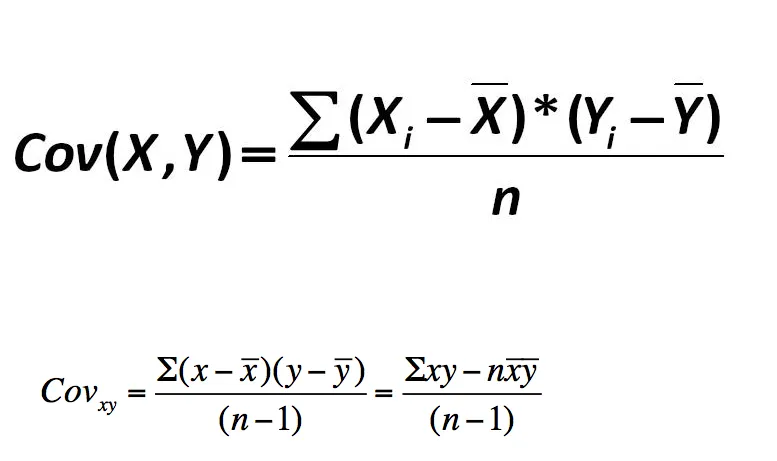
n^k行。所以,如果您的k=2向量(或Cypher集合)有1000个值,则双倍的UNWIND操作将使您处理1000^2 = 1,000,000行数据,然后在后续WITH子句中计算这些数据的平均值。尽管这不会影响答案,因为avg(1,2,3,4)=avg(1,2,3,4,1,2,3,4),但您会进行比所需更多的计算。 - Nicole Whiten^2扩展。所有这些答案对于小的n都是可以接受的,但是当n增长时,你会开始看到差异,这仍然是我上面描述的原因。 - Nicole White