应用程序不断接收名为
通过Eclipse Memory Analysis,每个
然而,每次对象数量约为10万个,这意味着所有对象的总大小大约为2GB。
要求是将所有的10万个对象加载到
因此,我想将对象序列化为
Report的对象,并将这些对象放入Disruptor以供三个不同的消费者使用。通过Eclipse Memory Analysis,每个
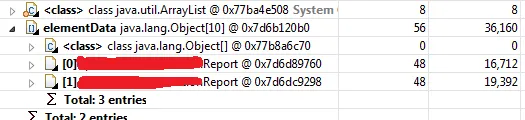
Report对象的保留堆大小平均为20KB。应用程序以-Xmx2048启动,表示应用程序的堆大小为2GB。然而,每次对象数量约为10万个,这意味着所有对象的总大小大约为2GB。
要求是将所有的10万个对象加载到
Disruptor中,以便消费者异步地消费数据。但如果每个对象的大小达到20KB,这是不可能实现的。因此,我想将对象序列化为
String并进行压缩:private static byte[] toBytes(Serializable o) throws IOException {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(o);
oos.close();
return baos.toByteArray();
}
private static String compress(byte[] str) throws IOException {
ByteArrayOutputStream out = new ByteArrayOutputStream();
GZIPOutputStream gzip = new GZIPOutputStream(out);
gzip.write(str);
gzip.close();
return new String(Base64Coder.encode(out.toByteArray()));
}
在使用compress(toBytes(Report))进行压缩后,对象的大小变小了:
压缩前
压缩后
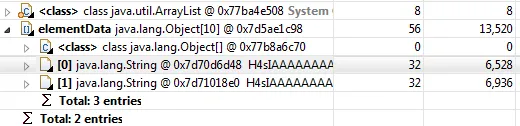
现在对象的字符串大小约为6KB,这是一个更好的结果。
以下是我的问题:
是否有其他数据格式比字符串更小?
每次调用序列化和压缩都会创建像
ByteArrayOutputStream、ObjectOutputStream等对象。我不想创建太多这样的对象,因为我需要迭代100,000次。如何设计代码,使得像ByteArrayOutputStream、ObjectOutputStream这样的对象只创建一次,并在每次迭代中重复使用?消费者需要对来自
Disruptor的字符串进行反序列化和解压缩。如果我有三个消费者,那么我需要三次反序列化和解压缩。有什么解决方法吗?
更新:
正如@BoristheSpider建议的那样,序列化和压缩应该在一次操作中执行:
private static byte[] compressObj(Serializable o) throws IOException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
GZIPOutputStream zos = new GZIPOutputStream(bos);
ObjectOutputStream ous = new ObjectOutputStream(zos);
ous.writeObject(o);
zos.finish();
bos.flush();
return bos.toByteArray();
}
byte[]然后再压缩它呢? - Boris the SpiderByteArrayOutputStream包装在一个GZIPOutputStream中,然后再包装在ObjectOutputStream中。这样可以在一次操作中序列化和压缩。 - Boris the SpiderString之前,您拥有的字节数组要紧凑得多。为什么不保留字节数组而不是创建String?有时您可能希望解压报告(否则根本不需要存储它),到那时您将再次需要一个字节数组。 - Holgerbyte[]更小。在我的情况下,对象大小为20k,String大小为6k,但是byte[]大约只有2k。 - macemers