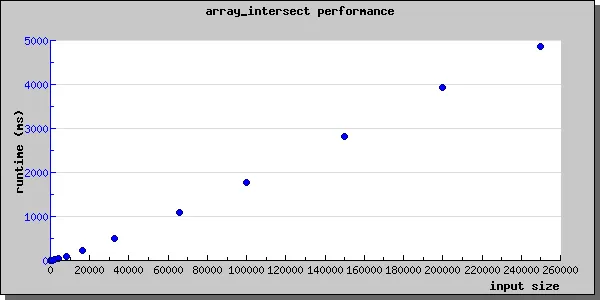
考虑下面的脚本。两个数组仅有三个值。使用array_intersect()函数比较这两个数组时,结果很快。
<?php
$arrayOne = array('3', '4', '5');
$arrayTwo = array('4', '5', '6');
$intersect = array_intersect($arrayOne, $arrayTwo);
print_r($intersect );
?>
我的问题是array_intersect()的效率如何。如果我们比较两个数组,每个数组都有1000个值,是否会产生更好的结果?我们需要使用一些散列函数来快速处理查找共同值吗,这将是有效的吗?我需要您的建议......
我正在开发一个应用程序。如果一个人通过Facebook登录,则该应用程序将获取他的朋友列表,并查找是否有任何朋友在我的应用程序中进行了评论,并向他显示。大致上一个朋友在Facebook上可能有200到300个朋友,而数据库中有超过1000个记录。我需要找到一种有效的方式来高效地做到这一点……