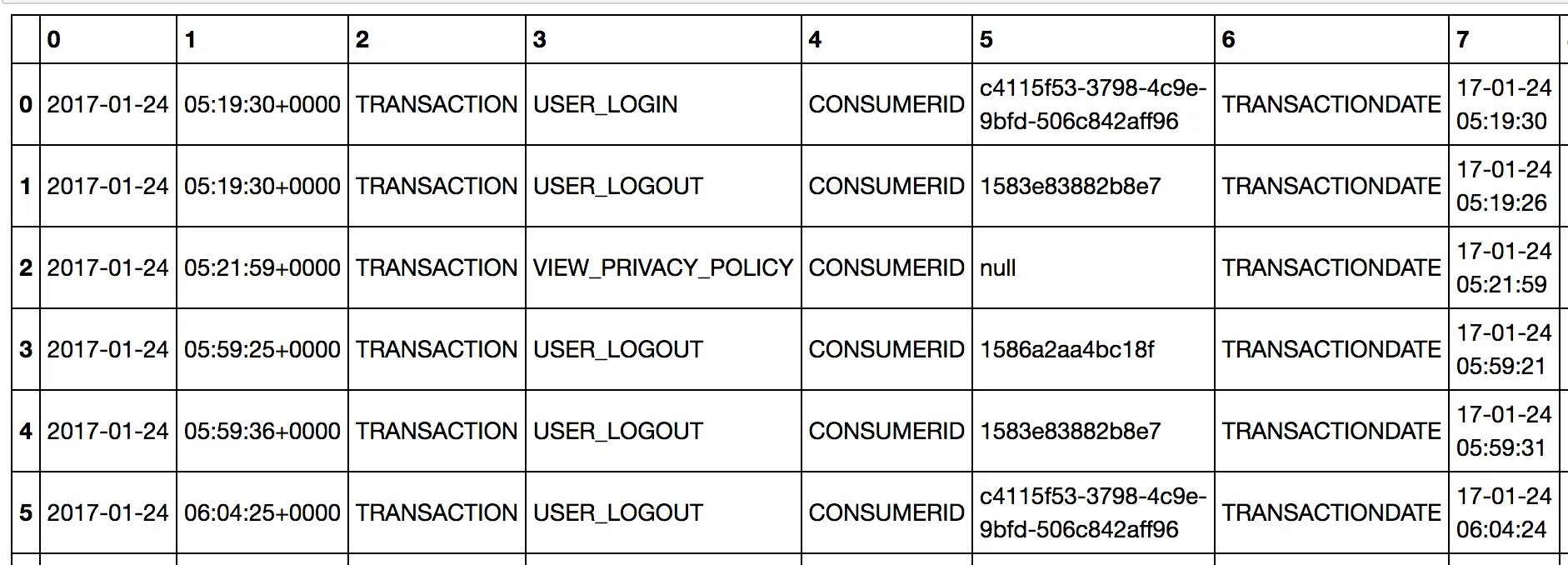
我有一个CSV文件,其中不同的列之间有三种不同的分隔符,分别是'|'、','和';'。
如何使用Python解析这个CSV文件?
我的数据如下:
2017-01-24|05:19:30+0000|TRANSACTIONDelim_secondUSER_LOGINDelim_firstCONSUMERIDDelim_secondc4115f53-3798-4c9e-9bfd-506c842aff96Delim_firstTRANSACTIONDATEDelim_second17-01-24 05:19:30Delim_firstCHANNELIDDelim_secondDelim_firstSHOWIDDelim_secondDelim_firstEPISODEIDDelim_secondDelim_firstBUSINESSUNITDelim_secondnullDelim_firstAIRINGDATEDelim_second|**
2017-01-24|05:19:30+0000|TRANSACTIONDelim_secondUSER_LOGOUTDelim_firstCONSUMERIDDelim_second1583e83882b8e7Delim_firstTRANSACTIONDATEDelim_second17-01-24 05:19:26Delim_firstCHANNELIDDelim_secondDelim_firstSHOWIDDelim_secondDelim_firstEPISODEIDDelim_secondDelim_firstBUSINESSUNITDelim_secondbu002Delim_firstAIRINGDATEDelim_second24-Jan-2017|**
2017-01-24|05:21:59+0000|TRANSACTIONDelim_secondVIEW_PRIVACY_POLICYDelim_firstCONSUMERIDDelim_secondnullDelim_firstTRANSACTIONDATEDelim_second17-01-24 05:21:59Delim_firstCHANNELIDDelim_secondDelim_firstSHOWIDDelim_secondDelim_firstEPISODEIDDelim_secondDelim_firstBUSINESSUNITDelim_secondnullDelim_firstAIRINGDATEDelim_second|**
2017-01-24|05:59:25+0000|TRANSACTIONDelim_secondUSER_LOGOUTDelim_firstCONSUMERIDDelim_second1586a2aa4bc18fDelim_firstTRANSACTIONDATEDelim_second17-01-24 05:59:21Delim_firstCHANNELIDDelim_secondDelim_firstSHOWIDDelim_secondDelim_firstEPISODEIDDelim_secondDelim_firstBUSINESSUNITDelim_secondbu002Delim_firstAIRINGDATEDelim_second24-Jan-2017|**
2017-01-24|05:59:36+0000|TRANSACTIONDelim_secondUSER_LOGOUTDelim_firstCONSUMERIDDelim_second1583e83882b8e7Delim_firstTRANSACTIONDATEDelim_second17-01-24 05:59:31Delim_firstCHANNELIDDelim_secondDelim_firstSHOWIDDelim_secondDelim_firstEPISODEIDDelim_secondDelim_firstBUSINESSUNITDelim_secondbu002Delim_firstAIRINGDATEDelim_second24-Jan-2017|**
2017-01-24|06:04:25+0000|TRANSACTIONDelim_secondUSER_LOGOUTDelim_firstCONSUMERIDDelim_secondc4115f53-3798-4c9e-9bfd-506c842aff96Delim_firstTRANSACTIONDATEDelim_second17-01-24 06:04:24Delim_firstCHANNELIDDelim_secondDelim_firstSHOWIDDelim_secondDelim_firstEPISODEIDDelim_secondDelim_firstBUSINESSUNITDelim_secondbu002Delim_firstAIRINGDATEDelim_second|**
2017-01-24|06:05:07+0000|TRANSACTIONDelim_secondUSER_LOGINDelim_firstCONSUMERIDDelim_secondc4115f53-3798-4c9e-9bfd-506c842aff96Delim_firstTRANSACTIONDATEDelim_second17-01-24 06:05:07Delim_firstCHANNELIDDelim_secondDelim_firstSHOWIDDelim_secondDelim_firstEPISODEIDDelim_secondDelim_firstBUSINESSUNITDelim_secondnullDelim_firstAIRINGDATEDelim_second|**
2017-01-24|06:05:07+0000|TRANSACTIONDelim_secondUSER_LOGINDelim_firstCONSUMERIDDelim_secondc4115f53-3798-4c9e-9bfd-506c842aff96Delim_firstTRANSACTIONDATEDelim_second17-01-24 06:05:07Delim_firstCHANNELIDDelim_secondDelim_firstSHOWIDDelim_secondDelim_firstEPISODEIDDelim_secondDelim_firstBUSINESSUNITDelim_secondbu002Delim_firstAIRINGDATEDelim_second|**