在Java中,HashMap、LinkedHashMap和TreeMap有什么区别?
我在输出中没有看到任何区别,因为这三个都有keySet和values。
另外,Hashtable是什么?
我在输出中没有看到任何区别,因为这三个都有keySet和values。
另外,Hashtable是什么?
Map<String, String> m1 = new HashMap<>();
m1.put("map", "HashMap");
m1.put("schildt", "java2");
m1.put("mathew", "Hyden");
m1.put("schildt", "java2s");
print(m1.keySet());
print(m1.values());
SortedMap<String, String> sm = new TreeMap<>();
sm.put("map", "TreeMap");
sm.put("schildt", "java2");
sm.put("mathew", "Hyden");
sm.put("schildt", "java2s");
print(sm.keySet());
print(sm.values());
LinkedHashMap<String, String> lm = new LinkedHashMap<>();
lm.put("map", "LinkedHashMap");
lm.put("schildt", "java2");
lm.put("mathew", "Hyden");
lm.put("schildt", "java2s");
print(lm.keySet());
print(lm.values());
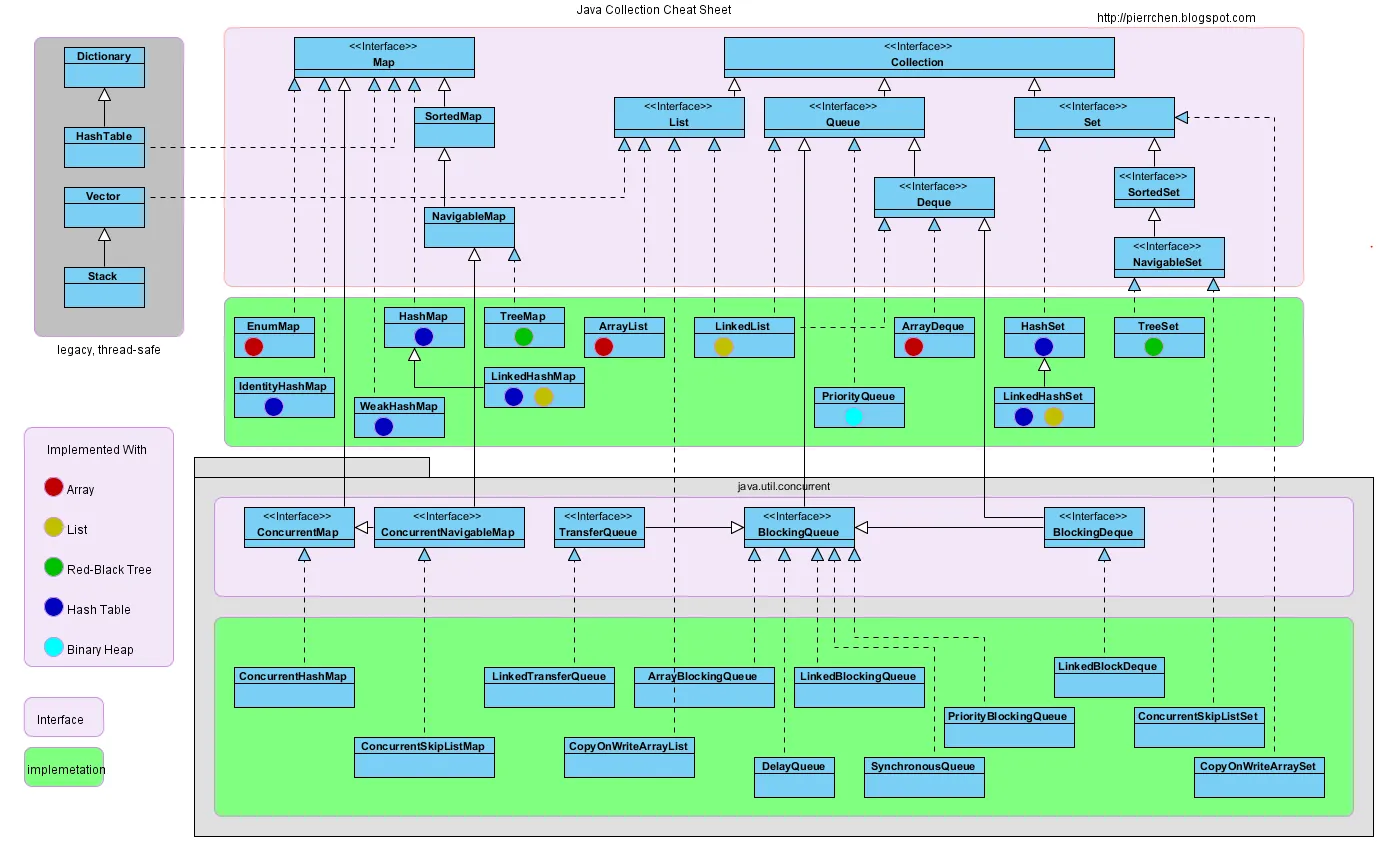
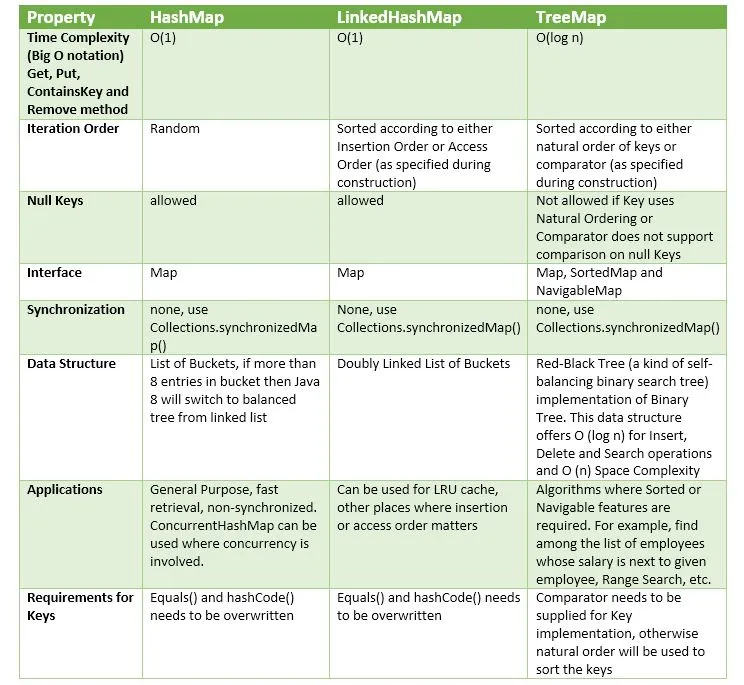
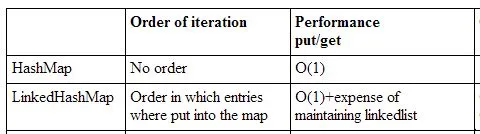 TreeMap是SortedMap的一种实现。由于自然排序,put、get和containsKey操作的复杂度为O(log n)。
TreeMap是SortedMap的一种实现。由于自然排序,put、get和containsKey操作的复杂度为O(log n)。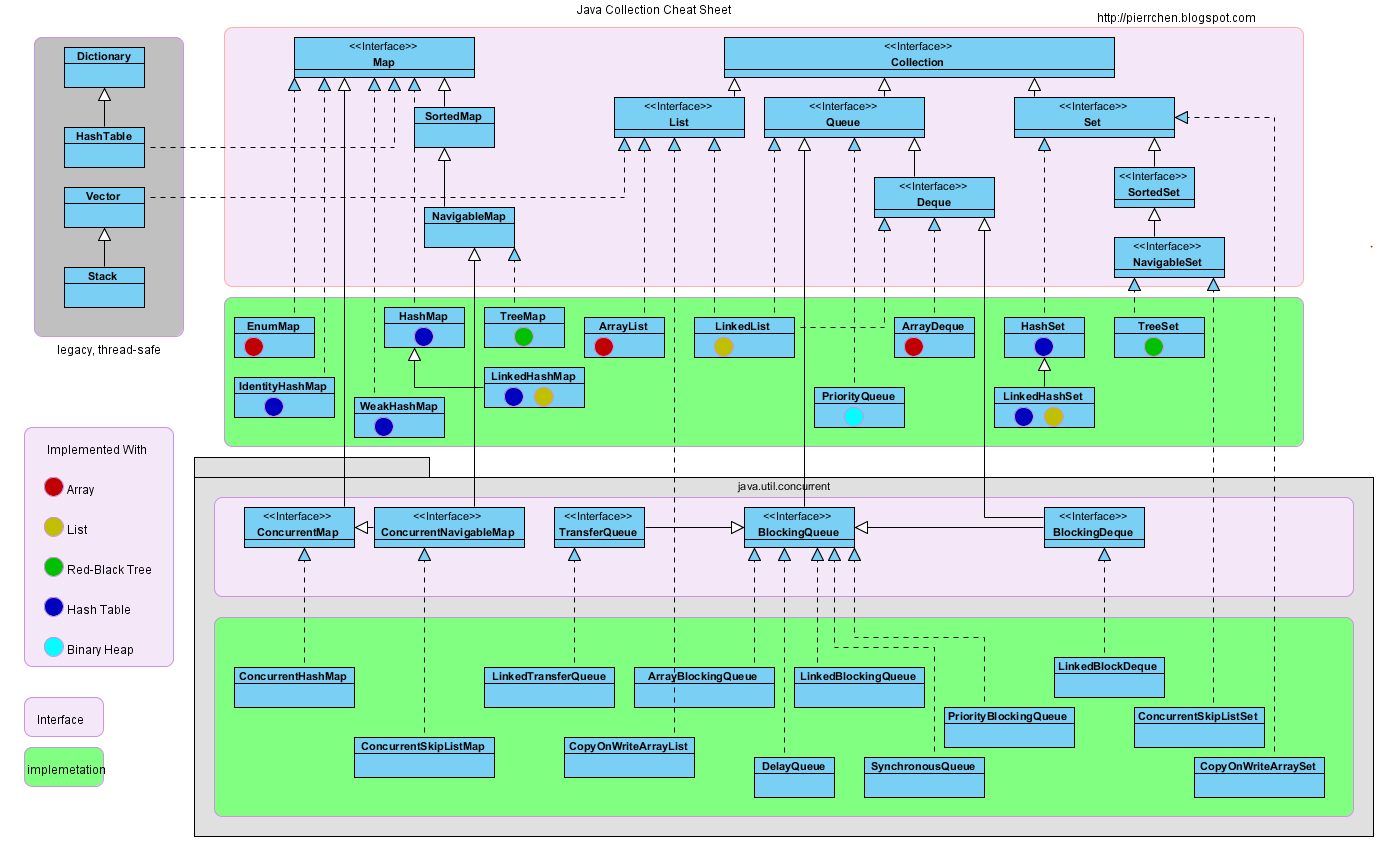{kind=link}