好的,这会很有趣。我们将从C++中函数指针的极其抽象的概念一直深入到汇编代码层面,并且由于我们遇到了一些特定的混淆,我们甚至能够讨论堆栈!
让我们从高度抽象的角度开始,因为显然你是从这方面开始的。你有一个函数 char** fun(),正在与它交互。现在,在这个抽象级别上,我们可以看看哪些操作可以在函数指针上执行:
- 我们可以测试两个函数指针是否相等。如果它们指向同一个函数,则两个函数指针是相等的。
- 我们可以在这些指针上进行不等式测试,从而允许我们对这样的指针进行排序。
- 我们可以解引用函数指针,这会产生一个“函数”类型,但它实际上很难理解,我选择暂时忽略它。
- 我们可以使用你使用的符号调用函数指针:
fun_ptr()。这个的含义与调用被指向的任何函数相同。
这就是它们在抽象级别上所做的全部。在此之下,编译器可以自由地按照他们认为合适的方式进行实现。如果编译器希望有一个 FunctionPtrType,它实际上是程序中每个函数的一个大表的索引,那么他们可以这样做。
然而,通常情况下并不是这样实现的。当将C++编译成汇编/机器代码时,我们倾向于利用尽可能多的特定于体系结构的技巧,以节省运行时间。在现实计算机上,几乎总会有一种“间接跳转”操作,它读取一个变量(通常是寄存器),并跳转到开始执行存储在该内存地址处的代码。几乎所有的函数都被编译为连续的指令块,因此如果您跳转到块中的第一个指令,它会逻辑地调用该函数。第一个指令的地址恰好满足C ++的函数指针抽象概念所需的每个比较,并且它恰好是硬件需要使用间接跳转来调用函数的值!这是如此方便,以至于几乎每个编译器都选择以这种方式进行实现!
但是,当我们开始谈论为什么你认为你正在查看的指针与函数指针相同时,我们必须深入讨论一些更加微妙的内容:段。
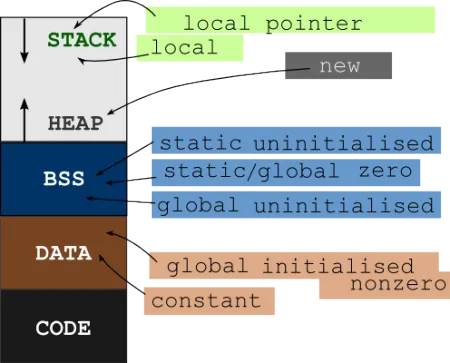
静态变量与代码存储在不同的内存空间。这么做有几个原因。首先,您希望代码尽可能紧凑。您不希望代码中充斥着用于存储变量的内存空间,否则会效率低下。您必须跳过各种内容,而不是直接执行。其次,还有一个更现代的原因:大多数计算机可以将某些内存标记为“可执行”的,而某些标记为“可写”的。这样做有助于防范一些非常恶意的黑客技巧。我们试图永远不要同时将某些东西标记为可执行和可写,以防黑客巧妙地找到方法来欺骗我们的程序,从而用自己的程序覆盖我们的一些函数!
因此,通常有一个名为.code的段(使用这种点号表示法只是因为它是许多体系结构中常用的表示方法)。在这个段中,您可以找到所有的代码。静态数据将存储在类似.bss的地方。所以您可能会发现您的静态字符串存储在远离操作它的代码的地方(通常至少相隔4kb,因为大多数现代硬件允许您在页面级别上设置执行或写入权限:在许多现代系统中,页面大小为4kb)。
现在是最后一部分...栈。您提到以令人困惑的方式在堆栈上存储数据,这表明可能有必要快速了解一下它。让我编写一个快速递归函数,因为它们更有效地演示了堆栈中发生的事情。
int fib(int x) {
if (x == 0)
return 0;
if (x == 1)
return 1;
return fib(x-1)+fib(x-2);
}
这个函数使用了一种相当低效但清晰易懂的方法来计算斐波那契数列。
我们有一个名为fib的函数。这意味着&fib始终是指向同一位置的指针,但显然我们正在多次调用fib,因此每个调用都需要自己的空间,对吗?
在堆栈上,我们有所谓的“帧”。“帧”并不是函数本身,而是允许该特定函数调用使用的内存部分。每次调用函数(比如fib),都会为其帧在堆栈上分配一些空间(或更严谨地说,在调用后它将在您进行调用之后分配)。
在我们的情况下,fib(x)显然需要在执行fib(x-2)时存储fib(x-1)的结果。它不能将其存储在函数本身中,甚至不能将其存储在.bss段中,因为我们不知道递归多少次。相反,它在堆栈上分配空间来存储其自己的fib(x-1)结果的副本,而fib(x-2)则在其自己的帧中(使用完全相同的函数和相同的函数地址)进行操作。当fib(x-2)返回时,fib(x)只需加载那个旧值(它肯定没有被任何其他人触摸过),加上结果并返回!
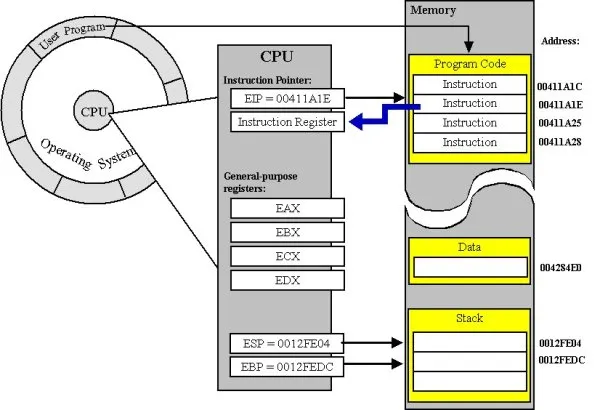
它是如何做到这一点的?实际上,几乎所有处理器都有一些硬件支持栈。在x86上,这称为ESP寄存器(扩展堆栈指针)。程序通常将其视为指向下一个可以开始存储数据的堆栈位置的指针。您可以随意移动此指针以建立自己的帧空间,并移动。执行完成后,您应该将所有内容移回。
事实上,在大多数平台上,您的函数中的第一条指令不是最终编译版本中的第一条指令。编译器注入了一些额外的操作来为您管理这个堆栈指针,使您甚至无需担心它。在某些平台上(如x86_64),这种行为甚至经常是强制性的,并在ABI中指定!
总之,我们有:
.code段——存储函数指令的地方。函数指针将指向其中的第一条指令。这个段通常标记为“只执行/只读”,在它被加载后,防止程序对其进行写入。.bss段——存储您的静态数据的地方,因为如果要成为数据,它不能是“只执行”.code段的一部分。- 堆栈——您的函数可以在此存储帧,在帧中仅跟踪当前实例所需的数据,而不需要更多。 (大多数平台也使用此功能来存储有关在函数完成后返回何处的信息)
- 堆——此答案中没有出现此项,因为您的问题不包括任何堆活动。但是,为了完整起见,我将在此留下它,以便以后不会让您感到惊
栈上。这样函数就可以利用推入和弹出操作。 - Greg Merror: invalid conversion from ‘const char**’ to ‘char**’ [-fpermissive]。 - Amit Upadhyay