来自链接: 什么是load/store relaxed原子和普通变量之间的区别?
我被以下回答深深打动:
使用原子变量解决了这个问题 - 通过使用原子操作,所有线程都保证读取到最新的写入值,即使内存顺序是放松的。
今天,我阅读了下面的链接: https://preshing.com/20140709/the-purpose-of-memory_order_consume-in-cpp11/
atomic<int*> Guard(nullptr);
int Payload = 0;
线程1:
Payload = 42;
Guard.store(&Payload, memory_order_release);
线程2:
g = Guard.load(memory_order_consume);
if (g != nullptr)
p = *g;
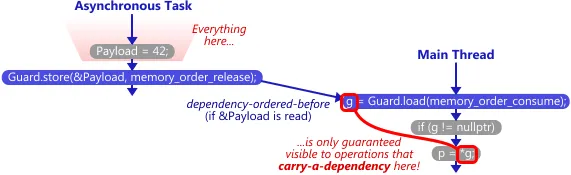
问题: 我了解到数据依赖性可以防止相关指令被重新排序。 但我认为这显然是为了确保执行结果的正确性,不管是否存在consume-release语义。 因此,我想知道consume-release真正的作用。噢,也许它使用数据依赖性来防止指令重新排序,同时确保有效载荷的可见性?
所以
如果我做到以下两点,1.防止指令重新排序2.确保非原子变量有效载荷的可见性,能否使用memory_order_relaxed获得相同的正确结果:
atomic<int*> Guard(nullptr);
volatile int Payload = 0; // 1.Payload is volatile now
// 2.Payload.assign and Guard.store in order for data dependency
Payload = 42;
Guard.store(&Payload, memory_order_release);
// 3.data Dependency make w/r of g/p in order
g = Guard.load(memory_order_relaxed);
if (g != nullptr)
p = *g; // 4. For 1,2,3 there are no reorder, and here, volatile Payload make the value of 42 is visable.
附加内容(因为Sneftel的回答):
1.Payload = 42; 使用volatile关键字可以使得Payload的读写操作直接在主存中进行而不是缓存,所以42将被写入内存。
2.Guard.store(&Payload, 可以使用任何MO标志进行写操作); Guard是非volatile的,但是是原子的
使用原子变量可以解决这个问题-通过使用原子性,所有线程都保证读取最新的写入值,即使内存顺序被放松。
实际上,原子操作始终是线程安全的,无论内存顺序如何!内存顺序不是针对原子操作的->它针对非原子数据。
所以在Guard.store执行后,Guard.load(使用任何MO标志进行读取)可以正确获取Payload的地址。然后从内存中正确获取42。
以上代码:
1.没有数据依赖的重排效应。
2.volatile Payload没有缓存效果
3.原子Guard不存在线程安全问题
我能获得正确的值-42吗?
回到主要问题
当您使用consume语义时,基本上是要让编译器在所有这些处理器系列上利用数据依赖关系。 因此,通常简单地更改memory_order_acquire为 memory_order_consume是不足够的。您还必须确保在C++源代码级别上存在数据依赖性链。
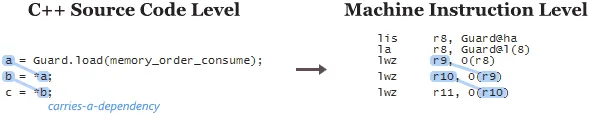
“您还必须确保在C++源代码级别上存在数据依赖性链。”
我认为C++源代码级别上的数据依赖链可以防止指令自然重排序。所以memory_order_consume到底是做了什么呢?
我能否使用memory_order_relaxed来实现与上述代码相同的结果?
附加内容结束
mo_relaxed进行黑客攻击,并且要交叉双臂(使用使编译器难以破坏数据依赖性的代码,例如通过值分支或删除它,如果可以证明只有一个可能的值)。请参见C++11:relaxed和consume之间的区别。 - Peter Cordes