我有一张包含如下数据的表格:
CREATE TABLE UDA_DATA
( uda VARCHAR2(20),
value_text VARCHAR2(4000)
);
Insert into UDA_DATA values('Material_ID','PBL000129 PBL000132 PBL000130 PBL000131 PBL000133');
Insert into UDA_DATA values('Material_ID','PBL0001341 PBL0001381 PBL0001351 PBL0001361 PBL0001371');
commit;
现在,如果我们从这个表中选择数据,它将会给出类似于以下的结果:
select * from UDA_DATA;
它会给出类似于以下内容的结果:
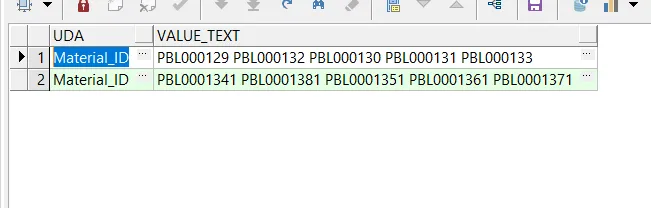
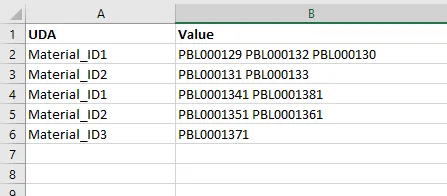
编写了一个递归CTE来实现这个结果:
with rcte (rn, uda, value, chunk_num, value_text) as (
select rownum,
uda,
substr(value_text, 1, 30),
1,
substr(value_text, 31)
from uda_data
union all
select rn,
uda,
substr(value_text, 1, 30),
chunk_num + 1,
substr(value_text, 31)
from rcte
where value_text is not null
)
select uda || chunk_num as uda, value
from rcte
order by rn, chunk_num;
这会产生如下结果:
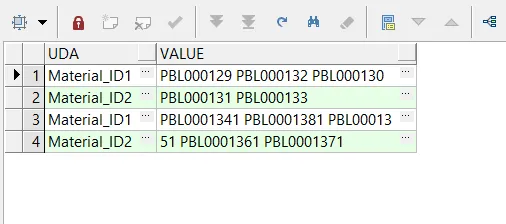
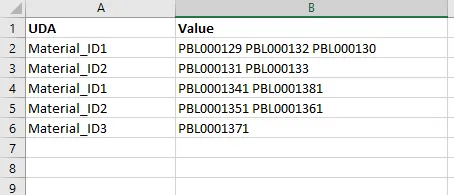
regexp_replace(value_text,'(.{1,30}+)\s','\1,')用适当的逗号替换了需要更改的空格。 - Sayan Malakshinov