我正在使用Cloud Firestore作为我的数据库。这是我的网页上创建一个名为“esequiz”的新文档到Cloud Firestore集合的表单代码。那么,如何编写代码,使其始终将1加到数据库中存在的文档数量?并且还要设置限制以在数据库内拥有文档的数量。
它目前可以使用,但会显示为自动生成的ID。如何使其从数字继续,就像我的当前文档一样?当我保存时,我想让它读取当前最后一个文档ID,或者只是计算文档数量,然后加1。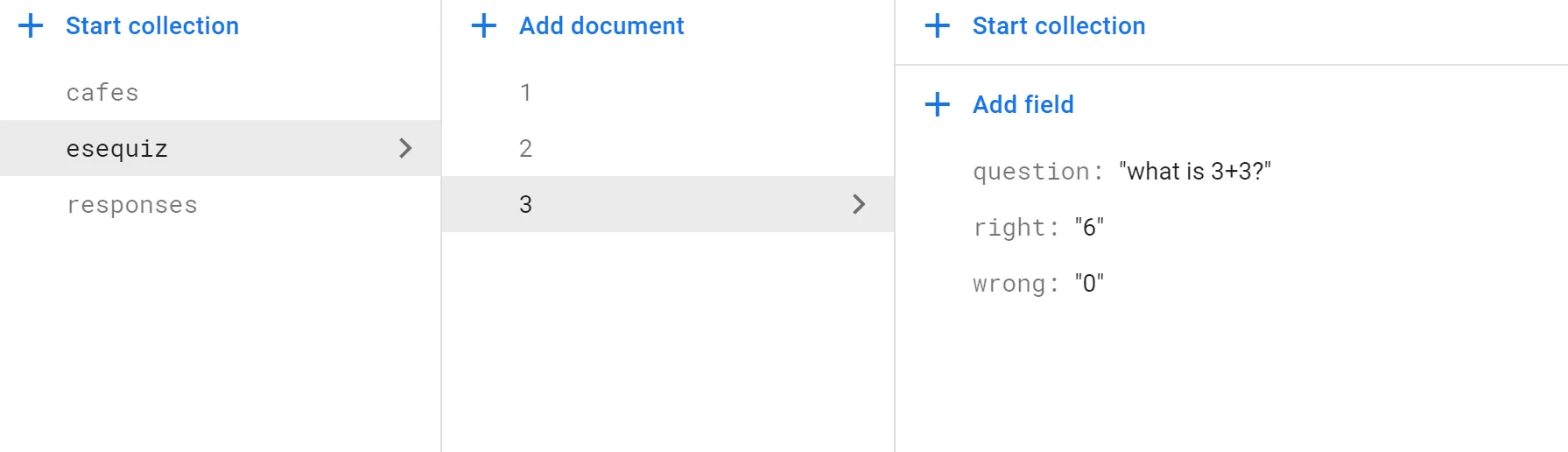 来自Andrei Cusnir的见解,Cloud Firestore不支持计算文档数。
来自Andrei Cusnir的见解,Cloud Firestore不支持计算文档数。
现在我正在尝试Andrei的第二种方法,按降序查询文档,然后使用.limit仅检索第一个文档。 更新
没有错误,但是下面的代码返回[object Promise]
我认为这是因为我没有指定将文档ID作为值提取出来,那么我该怎么做呢? 更新:最终解决方案
更新:最终解决方案
通过与Andrei的代码尝试,这里是最终可行的代码。非常感谢Andrei!
form.addEventListener('submit', (e) => {
e.preventDefault();
db.collection('esequiz').add({
question: form.question.value,
right: form.right.value,
wrong: form.wrong.value
});
form.question.value = '';
form.right.value = '';
form.wrong.value = '';
});
它目前可以使用,但会显示为自动生成的ID。如何使其从数字继续,就像我的当前文档一样?当我保存时,我想让它读取当前最后一个文档ID,或者只是计算文档数量,然后加1。
来自Andrei Cusnir的见解,Cloud Firestore不支持计算文档数。现在我正在尝试Andrei的第二种方法,按降序查询文档,然后使用.limit仅检索第一个文档。 更新
form.addEventListener('submit', (e) => {
e.preventDefault();
let query = db.collection('esequiz');
let getvalue = query.orderBy('id', 'desc').limit(1).get();
let newvalue = getvalue + 1;
db.collection('esequiz').doc(newvalue).set({
question: form.question.value,
right: form.right.value,
wrong: form.wrong.value
});
form.question.value = '';
form.right.value = '';
form.wrong.value = '';
});
没有错误,但是下面的代码返回[object Promise]
因此,当我的表单保存时,它保存为[object Promise]1,我不知道为什么会这样。有人能告诉我如何返回文档ID值而不是[object Promise]吗?let getvalue = query.orderBy('id', 'desc').limit(1).get();
我认为这是因为我没有指定将文档ID作为值提取出来,那么我该怎么做呢?
更新:最终解决方案通过与Andrei的代码尝试,这里是最终可行的代码。非常感谢Andrei!
let query = db.collection('esequiz');
//let getvalue = query.orderBy('id', 'desc').limit(1).get();
//let newvalue = getvalue + 1;
query.orderBy('id', 'desc').limit(1).get().then(querySnapshot => {
querySnapshot.forEach(documentSnapshot => {
var newID = documentSnapshot.id;
console.log(`Found document at ${documentSnapshot.ref.path}`);
console.log(`Document's ID: ${documentSnapshot.id}`);
var newvalue = parseInt(newID, 10) + 1;
var ToString = ""+ newvalue;
db.collection('esequiz').doc(ToString).set({
id: newvalue,
question: form.question.value,
right: form.right.value,
wrong: form.wrong.value
});
});
});
.length()而是.length,因为它不是一个函数而是一个属性。所以请尝试使用let x = db.collection('esequiz').doc.length;。 - johannchopin