当我们尝试使用Chrome的打印选项将包含CJK字符的网页保存为PDF时,我们遇到了问题。
在PDF中,Chrome渲染的字符在视觉上看起来相同,但Unicode不同。
以下是一个基本的HTML。
<HTML>
<HEAD>
Test Character
</HEAD>
<BODY>
子
</BODY>
</HTML>当我们尝试使用Chrome的打印选项将包含CJK字符的网页保存为PDF时,我们遇到了问题。
在PDF中,Chrome渲染的字符在视觉上看起来相同,但Unicode不同。
以下是一个基本的HTML。
<HTML>
<HEAD>
Test Character
</HEAD>
<BODY>
子
</BODY>
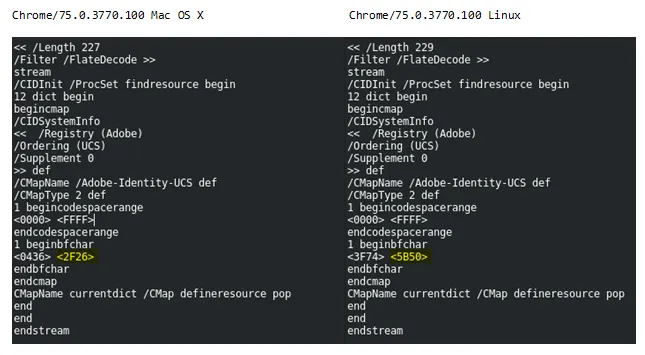
</HTML>STSongti-SC-Regular,其字形ID为十六进制0436。U+5B50。下面是peepdf实用程序的输出示例比较:
SkFontHost_mac.cpp文件中的onCharsToGlyphs()和populate_glyph_to_unicode()方法中完成。在macOS上,这两个方法都依赖于Core Text库中的CTFontGetGlyphsForCharacters()调用,迭代每个可能的字符以构建映射表。NSString *fontName = @"STSongti-SC-Regular";
CTFontRef fontRef = CTFontCreateWithName((CFStringRef)fontName, 10.0, NULL);
CFDataRef bitmap = CFCharacterSetCreateBitmapRepresentation(kCFAllocatorDefault, CTFontCopyCharacterSet(fontRef));
CFIndex length = CFDataGetLength(bitmap);
const UInt8* bits = CFDataGetBytePtr(bitmap);
for (int i = 0; i < length; i++) {
int mask = bits[i];
if (!mask)
continue;
for (int j = 0; j < 8; j++) {
CGGlyph glyph;
UniChar unichar = (UniChar)((i << 3) + j);
if (mask & (1 << j) && CTFontGetGlyphsForCharacters(fontRef, &unichar, &glyph, 1)) {
NSLog(@"%04x %04x", glyph, unichar);
}
}
}
浏览输出结果,我们的字形代码有两个字符编码:
0436 2f26 0436 5b50
首先遇到的是 2f26,这很重要,因为在构建查找表时,如果字形已经有一个字符编码被确定(并且它的值 >= 0x20),则不会被覆盖:
if (CTFontGetGlyphsForCharacters(ctFont, utf16, glyphs, count)) {
// ...
if (glyphToUnicode[glyphs[0]] < 0x20) {
glyphToUnicode[glyphs[0]] = codepoint;
}
}
因此,我相信最终发生的是:
5B50 的 STSongti-SC-Regular 字形 id 为 0436。它在 pdf 中使用这个字形来表示 cjk 字符。STSongti-SC-Regular 的字形到字符码查找表。由于 0436 映射到两个代码,并且先遇到 2f26,所以记录的就是这个值,而这也是从文档中复制和粘贴时返回的值。