当我的数据通过Kafka发送并存储在S3上时,它的编码出现了问题。
使用Debezium MySQL连接器将其作为十进制数插入到Kafka中,该连接器遵循以下规则:
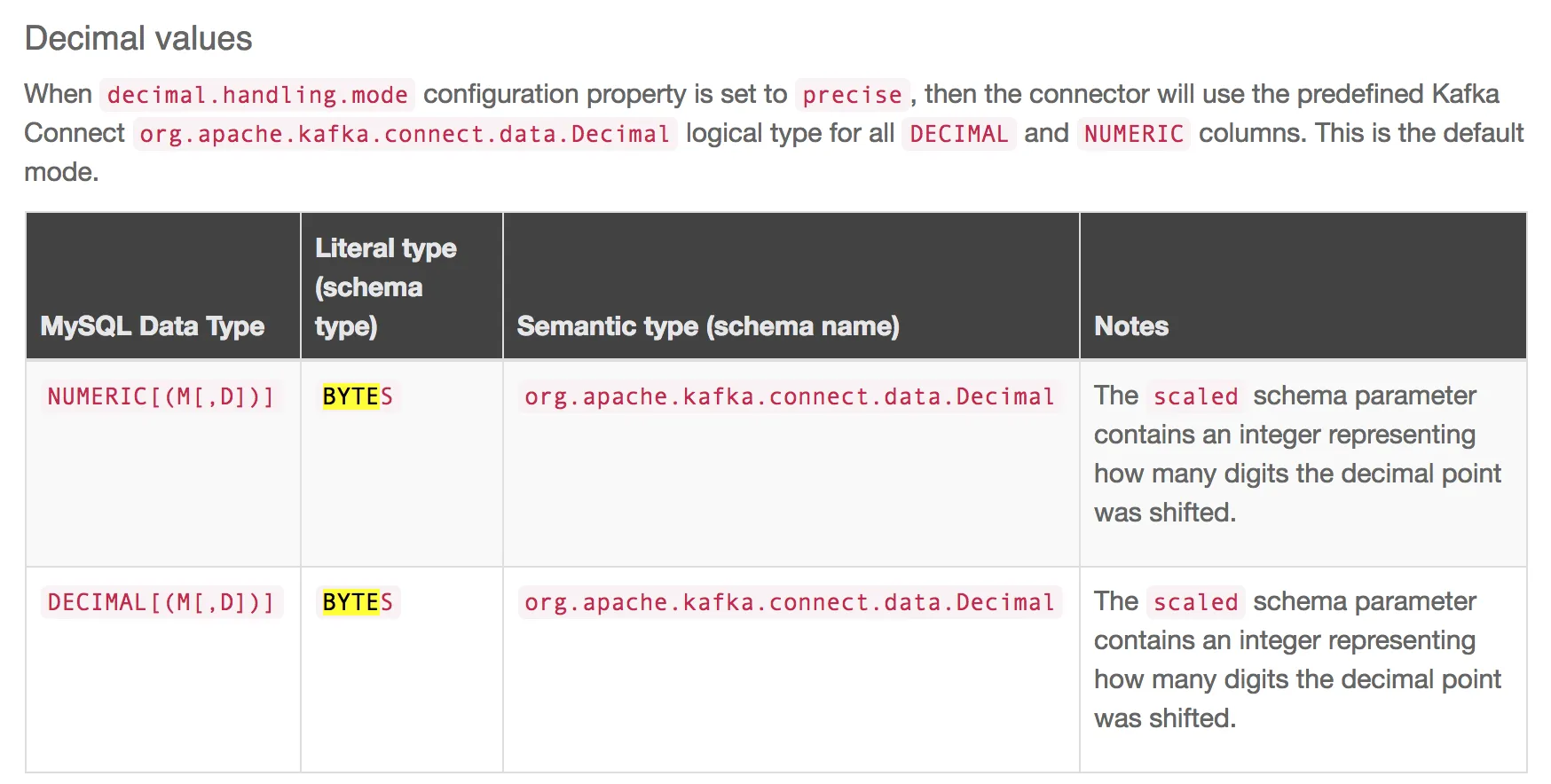
创建的Avro模式的相关部分如下:
{
"name": "PRICE_SELLING",
"type": [
"null",
{
"type": "bytes",
"scale": 2,
"precision": 64,
"connect.version": 1,
"connect.parameters": {
"scale": "2"
},
"connect.name": "org.apache.kafka.connect.data.Decimal",
"logicalType": "decimal"
}
],
"default": null
}
问题在于,当我从主题中读取数据并写入S3时,它最终以字母串的形式出现在S3中。我的直觉是字节是正确的,但它应该被表示为浮点数,而不是字符串。
示例: - 'JiU8' 应该是 24999.00 - 'JiDw' 应该是 24988.00 - 'RxFc' 应该是 46575.00 - 'LyZQ' 应该是 30900.00
我尝试使用 struct 和 ord,但似乎找不到正确的组合将其转换回浮点形式。
以下是我尝试过的一些方法:
>>> struct.unpack('f','JiU8');
(5.088121542939916e-05,)
>>> struct.unpack('>f','JiU8');
(3822926.0,)
我有一个Apache Spark的工作任务(使用Python 2.7),从S3读取数据并将其移动到OLAP数据库中,因此我希望在将数据插入数据库之前,在Python中解决数据问题。
struct模块的代码——看起来应该可以工作。 - martineau