我正在使用ItextSharp和c#,asp.net MVC生成PDF报告。然而,当我生成报告时,PDF会返回为空白(除了一个正常工作的页眉)。我希望得到您的帮助。
生成报告的代码如下:
using (var writer = PdfWriter.GetInstance(doc, ms))
{
// This sorts out the Header and Footer parts.
var headerFooter = new ReportHeaderFooter(reportsAccessor);
writer.PageEvent = headerFooter;
var rootPath = ConfigurationManager.AppSettings["SaveFileRootPath"];
string html = File.ReadAllText(rootPath + "/reports/report.html");
// Perform the parsing to PDF
doc.Open();
// The html needs to be sorted before this call.
StringReader sr = new StringReader(html);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, doc, sr);
doc.Close();
writer.Close();
res = ms.ToArray();
}
我知道有很多隐藏的内容,但为了论证起见,这里提供了它所生成并放入StringReader中的HTML示例:
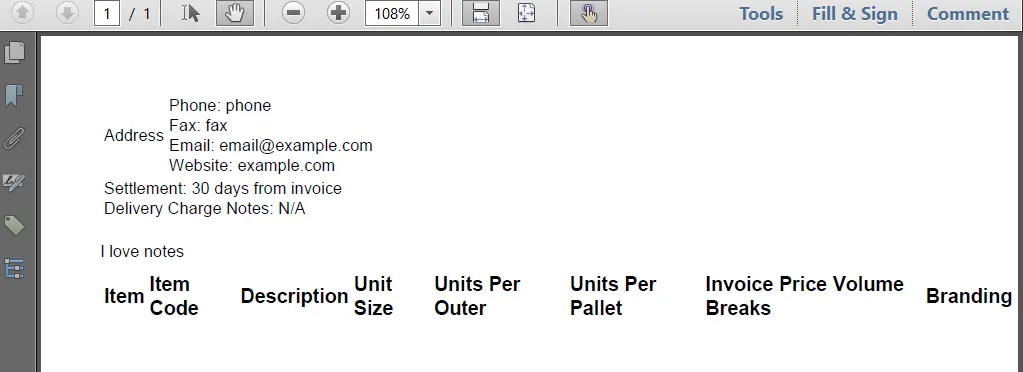
<table style="font-size:10pt">
<tr>
<td rowspan="4"> Address<br/> </td>
<td>Phone: phone</td>
</tr>
<tr>
<td>Fax: fax</td>
</tr>
<tr>
<td>Email: email@example.com</td>
</tr>
<tr>
<td>Website: example.com</td>
</tr>
<table>
<table style="font-size:10pt; width:100%">
<tr style="width:50%">
<td>Settlement: 30 days from invoice</td>
</tr>
<tr>
<td>Delivery Charge Notes: N/A</td>
</tr>
</table>
<p style="width:100%; font-size:10pt">
I love notes</p>
<table>
<tr style="font-weight:bold">
<td>Item</td>
<td>Item Code</td>
<td>Description</td>
<td>Unit Size</td>
<td>Units Per Outer</td>
<td>Units Per Pallet</td>
<td>Invoice Price Volume Breaks</td>
<td>Branding</td>
<td>Notes</td>
</tr>
</table>
然而,这段HTML生成了一个漂亮的空白PDF文件(不是我想要的)。我看不出有什么问题,希望能就以下两个问题得到一些帮助: [1] 为什么报告是空白的? [2] 如果这是解析错误,为什么没有显示错误信息,反而是一个空白报告?(是否有设置或参数可以抛出更有用的错误信息而不是空白报告?)
更新: 我已经添加了头/尾代码: public string HeaderTitle { get; set; } public IReportsAccessor ReportsAccessor { get; set; } public ReportHeaderFooter(IReportsAccessor reportsAccessor) { this.ReportsAccessor = reportsAccessor; }
public override void OnStartPage(PdfWriter writer, Document document)
{
base.OnStartPage(writer, document);
var rootPath = ConfigurationManager.AppSettings["SaveFileRootPath"];
GetReportImageResult imgInfo = ReportsAccessor.GetImage(4);
byte[] header_img = imgInfo.ReportImage;
string logoFn = rootPath + "/tmp/logo.png";
File.WriteAllBytes(logoFn, header_img);
string html = File.ReadAllText(rootPath + "/reports/report_header.html");
html = html.Replace("{{ title }}", HeaderTitle);
html = html.Replace("{{ logo_img }}", logoFn);
StringReader sr = new StringReader(html);
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, sr);
}
 我的代码和你的代码之间的一个主要区别是,我使用了iText/XML Worker 5.5.6(Java),而你使用的是iTextSharp/XML Worker(C#)。虽然Java iText和XML Worker与C# iTextSharp和XML Worker保持同步(因此应该具有相同的行为),但底层XML解析器是不同的。
我的代码和你的代码之间的一个主要区别是,我使用了iText/XML Worker 5.5.6(Java),而你使用的是iTextSharp/XML Worker(C#)。虽然Java iText和XML Worker与C# iTextSharp和XML Worker保持同步(因此应该具有相同的行为),但底层XML解析器是不同的。