我写的搜索功能速度有问题。以下是该函数的步骤:
以下是图示,显示了各种表之间可能形成的连接示例: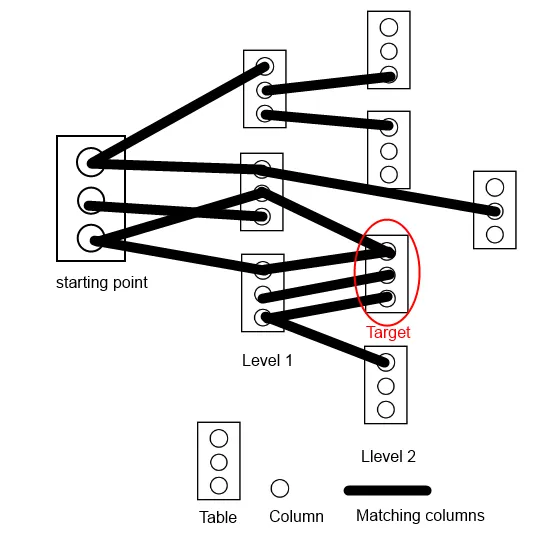 以下是我的代码:
以下是我的代码:
- 函数开始时需要两个表名参数:起始点和目标点
- 然后函数遍历一个包含50,000个元素的表-列组合列表,并检索所有与起始点表相关的组合。
- 然后,函数遍历每个检索到的组合,对于每个组合,再次遍历表-列组合列表,但这一次寻找匹配给定列的表。
- 最后,函数遍历从上一步返回的每个组合,对于每个组合,检查该表是否与目标表相同;如果是,则保存它,否则调用自身并传入该组合的表名。
以下是图示,显示了各种表之间可能形成的连接示例:
以下是我的代码:private void FindLinkingTables(List<TableColumns> sourceList, TableSearchNode parentNode, string targetTable, int maxSearchDepth)
{
if (parentNode.Level < maxSearchDepth)
{
IEnumerable<string> tableColumns = sourceList.Where(x => x.Table.Equals(parentNode.Table)).Select(x => x.Column);
foreach (string sourceColumn in tableColumns)
{
string shortName = sourceColumn.Substring(1);
IEnumerable<TableSearchNode> tables = sourceList.Where(
x => x.Column.Substring(1).Equals(shortName) && !x.Table.Equals(parentNode.Table) && !parentNode.Ancenstory.Contains(x.Table)).Select(
x => new TableSearchNode { Table = x.Table, Column = x.Column, Level = parentNode.Level + 1 });
foreach (TableSearchNode table in tables)
{
parentNode.AddChildNode(sourceColumn, table);
if (!table.Table.Equals(targetTable))
{
FindLinkingTables(sourceList, table, targetTable, maxSearchDepth);
}
else
{
table.NotifySeachResult(true);
}
}
}
}
}
EDIT: 分离TableSearchNode逻辑并添加属性和方法,以保证完整性。
//TableSearchNode
public Dictionary<string, List<TableSearchNode>> Children { get; private set; }
//TableSearchNode
public List<string> Ancenstory
{
get
{
Stack<string> ancestory = new Stack<string>();
TableSearchNode ancestor = ParentNode;
while (ancestor != null)
{
ancestory.Push(ancestor.tbl);
ancestor = ancestor.ParentNode;
}
return ancestory.ToList();
}
}
//TableSearchNode
public void AddChildNode(string referenceColumn, TableSearchNode childNode)
{
childNode.ParentNode = this;
List<TableSearchNode> relatedTables = null;
Children.TryGetValue(referenceColumn, out relatedTables);
if (relatedTables == null)
{
relatedTables = new List<TableSearchNode>();
Children.Add(referenceColumn, relatedTables);
}
relatedTables.Add(childNode);
}
Thanks in advance for your help!
if (!table.Table.Equals(targetTable))更改为if (table.Table.Equals(targetTable))并交换了内部语句,以便递归调用是最后一个语句。我不确定它在执行时如何翻译。如果您有更好的方法,请告诉我。顺便说一下,我已经以所有可能的方式出了大错(进程吃掉了1.5GB的RAM),所以不用担心 :) - Sinker