Scala 2.8 集合框架设计教程
1
前言
有一篇由Martin Odersky撰写的2.8集合遍历指南,这可能应该是您的第一个参考。此外,还补充了架构注释,对于那些想要设计自己的集合的人来说,这将特别有用。
这个答案的其余部分都是在任何这样的东西存在之前编写的(实际上是在2.8.0本身发布之前)。
您可以在Scala SID#3中找到有关它的论文。在那个领域的其他论文对于对Scala 2.7和2.8之间的差异感兴趣的人也应该很有趣。
我将从论文中选择性地引用,并搭配我的一些想法。 还有一些图片,由Matthias在decodified.com生成,并且原始的SVG文件可以在这里找到。
集合类/特征本身
实际上有三个层次结构的特征集合:一个用于可变集合,一个用于不可变集合,以及一个不对集合做任何假设。
还有一种区别并行、串行和可能并行集合的方法,这是在Scala 2.9中引入的。我将在下一节中谈论它们。本节描述的层次结构仅涉及非并行集合。
以下图片显示了Scala 2.8引入的非特定层次结构:
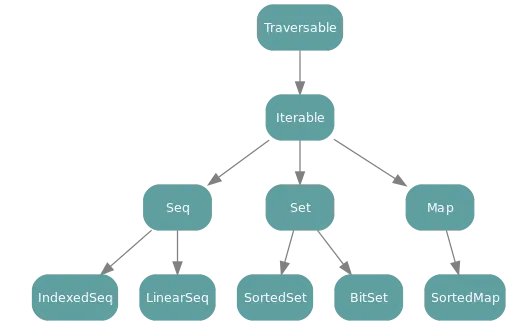
所有显示的元素都是特征。在其他两个层次结构中,还存在直接继承特征的类,以及可以通过隐式转换为包装器类而被视为属于该层次结构的类。这些图的图例可以在它们后面找到。
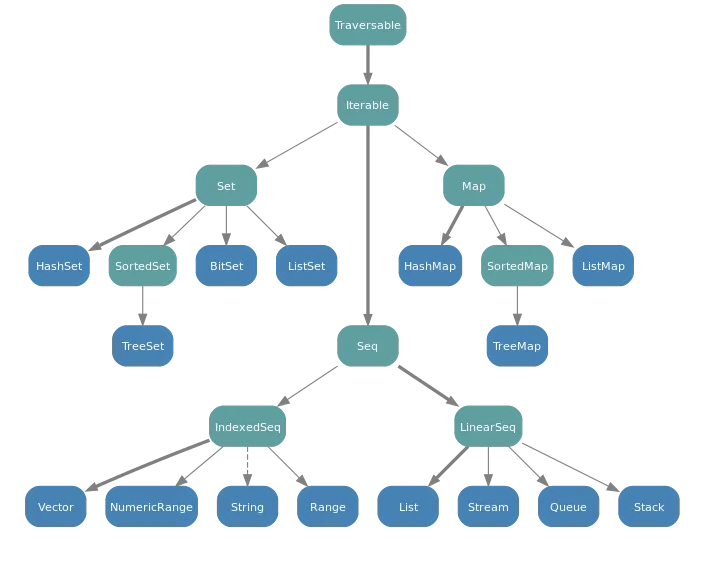
不可变层次结构图:
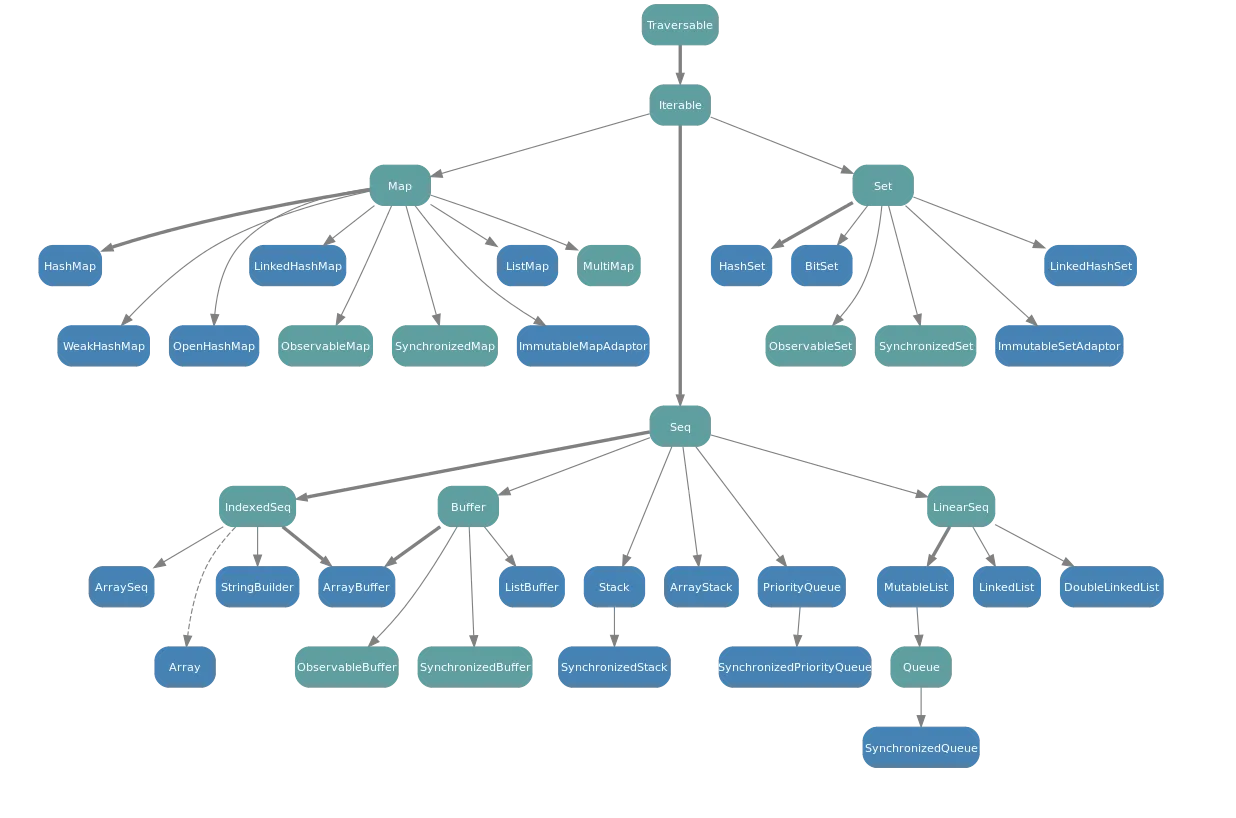
可变层次结构图:
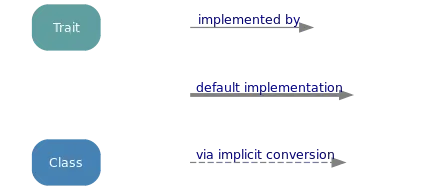
图例:
以下是集合层次结构的缩写ASCII表示法,供那些无法看到图像的人使用。
Traversable
|
|
Iterable
|
+------------------+--------------------+
Map Set Seq
| | |
| +----+----+ +-----+------+
Sorted Map SortedSet BitSet Buffer Vector LinearSeq
并行集合
Scala 2.9引入了并行集合,设计目标之一是使它们的使用尽可能无缝。简单来说,可以用并行集合替换非并行(串行)集合,并立即获得好处。
然而,由于直到那时所有集合都是串行的,许多使用它们的算法假设并依赖于它们是串行的事实。将这些假设传递给并行集合的方法会失败。因此,前面一节中描述的整个层次结构强制执行串行处理。
为支持并行集合创建了两个新的层次结构。
并行集合层次结构具有相同的特征名称,但前缀为Par:ParIterable,ParSeq,ParMap和ParSet。请注意,没有ParTraversable,因为支持并行访问的任何集合都能够支持更强的ParIterable特质。它也没有序列化层次结构中存在的某些更专业的特征。整个层次结构在目录scala.collection.parallel下找到。
实现并行集合的类也不同,有可变和不可变并行集合的ParHashMap和ParHashSet,以及实现immutable.ParSeq的ParRange和ParVector,以及实现mutable.ParSeq的ParArray。
还存在另一个层次结构,它与串行和并行集合的特质相似,但前缀为Gen:GenTraversable,GenIterable,GenSeq,GenMap和GenSet。这些特征都是并行和串行集合的父级。这意味着接受Seq的方法不能接收并行集合,但接受GenSeq的方法应该能够处理串行和并行集合。
由于这些层次结构的结构方式,为Scala 2.8编写的代码与Scala 2.9完全兼容,并要求串行行为。如果不重写,它不能利用并行集合,但所需的更改非常小。
使用并行集合
可以通过在其上调用方法par将任何集合转换为并行集合。同样,可以通过在其上调用方法seq将任何集合转换为串行集合。
如果集合已经是所请求的类型(并行或串行),则不会进行转换。但是,如果在并行集合上调用seq或在串行集合上调用par,则将生成具有所请求特性的新集合。
seq和从集合元素创建Seq的toSeq。在并行集合上调用toSeq将返回ParSeq,而不是串行集合。主要特征
虽然有许多实现类和子特征,但层次结构中有一些基本特征,每个特征提供更多的方法或更具体的保证,但减少了可以实现它们的类的数量。
在以下分节中,我将简要描述主要特征及其背后的思想。
特征可遍历一次
这个特征与下面描述的特征
Traversable非常相似,但有一个限制,即您只能使用它一次。也就是说,在TraversableOnce 上调用的任何方法都可能使其不能再使用。这个限制使得相同的方法可以在集合和
Iterator之间共享。这使得能够使用一个与Iterator一起工作但不使用Iterator特定方法的方法,实际上能够使用任何集合,加上迭代器,如果重写以接受TraversableOnce。由于
TraversableOnce统一了集合和迭代器,所以它不出现在先前的图表中,这些图表只关注集合。特征可遍历
在集合层次结构的顶部是特征
Traversable。它唯一的抽象操作是def foreach[U](f: Elem => U)
该操作旨在遍历集合的所有元素,并对每个元素应用给定的操作f。应用仅出于其副作用而完成;实际上,任何f的函数结果都将被foreach丢弃。
可遍历对象可以是有限的或无限的。无限遍历对象的一个例子是自然数流Stream.from(0)。方法hasDefiniteSize指示集合是否可能为无限。如果hasDefiniteSize返回true,则集合一定是有限的。如果返回false,则集合尚未完全详细说明,因此它可能是无限的或有限的。
该类定义了可以高效地基于foreach实现的方法(超过40个)。
可迭代特质
该特质声明了一个抽象方法iterator,它返回一个迭代器,按顺序返回集合的所有元素。在Iterable中,foreach方法是基于iterator实现的。 Iterable的子类通常通过直接实现foreach以提高效率。
Iterable类还向Traversable添加了一些不太常用的方法,只有在有iterator时才能有效地实现。它们如下所述:
xs.iterator An iterator that yields every element in xs, in the same order as foreach traverses elements.
xs takeRight n A collection consisting of the last n elements of xs (or, some arbitrary n elements, if no order is defined).
xs dropRight n The rest of the collection except xs takeRight n.
xs sameElements ys A test whether xs and ys contain the same elements in the same order
其他特性
Iterable 的后面有三个继承自它的基本特性:Seq、Set 和 Map。这三种特性都有一个 apply 方法,并且都实现了 PartialFunction 特性,但在每种情况下 apply 的含义是不同的。
我相信 Seq、Set 和 Map 的含义是直观的。在它们之后,类别会分为具体实现,提供特定的性能保证和相应的方法。还可用一些特性进行进一步的精炼,如 LinearSeq、IndexedSeq 和 SortedSet。
以下列表可能需要改进。请留下评论提出建议,我会进行修正。
Hello! I'll do my best to answer your questions concisely and accurately. Please feel free to ask me anything!为了实现最大化的代码重用,这些具有特定结构(可遍历、映射等)的类的具体通用实现在Like类中完成。然后,旨在供一般使用的类覆盖了可以进行优化的选定方法。
类的伴生方法(例如List.companion)是用于什么目的的。
类的构建器,即知道如何创建该类的实例以便可以被map等方法使用的对象,是通过其伴生对象中的一个方法创建的。因此,要构建X类型的对象,我需要从X类的伴生对象获取该构建器。不幸的是,在Scala中没有办法从X类到达X对象。因此,在每个X实例中定义了一个方法companion,该方法返回类X的伴生对象。
尽管在普通程序中可能会对这种方法有些用处,但它的目标是在集合库中启用代码重用。
我如何知道在某个给定点上隐式对象都有哪些。
你不必关心这个问题。它们是隐式的,正是因为你不需要弄清楚如何使其工作。
这些隐式存在是为了使集合上的方法能够在父类上定义,但仍返回相同类型的集合。例如,map方法是在TraversableLike上定义的,但如果您在List上使用它,则会返回一个List。
3
原文链接