我了解到每个用户进程拥有一个地址空间,其中包含有效的内存位置,该进程可以引用。我知道进程可以调用系统调用并向其传递参数,就像任何其他库函数一样。这似乎表明所有系统调用都在进程地址空间中共享内存等,但也许这只是一个错觉,因为在高级编程语言中,系统调用看起来像任何其他函数,当进程调用它时。
但是,现在让我更深入地分析一下发生了什么。编译器如何编译系统调用?它可能会将进程提供的系统调用名称和参数推送到堆栈中,然后将汇编指令例如“TRAP”放置在程序中--基本上是调用软件中断的汇编指令。
硬件执行这个TRAP汇编指令,首先将模式位从用户切换到内核,然后将代码指针设置为中断服务例程的开始位置。从此处开始,在内核模式下执行ISR,该ISR从堆栈中提取参数(这是可能的,因为内核可以访问任何内存位置,甚至是由用户进程拥有的内存位置),执行系统调用,并最终释放CPU,再次切换模式位,用户进程从离开的地方继续执行。
我的理解正确吗?
下面是我理解的简单图示: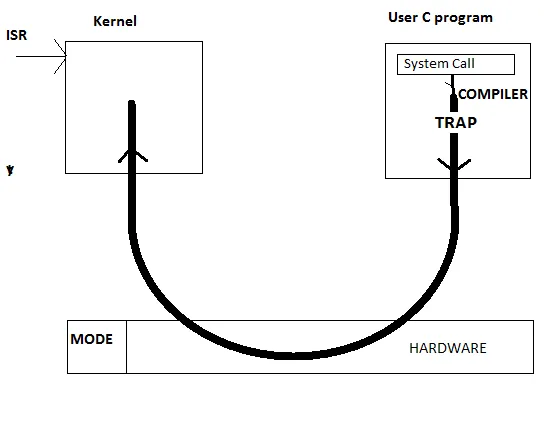
但是,现在让我更深入地分析一下发生了什么。编译器如何编译系统调用?它可能会将进程提供的系统调用名称和参数推送到堆栈中,然后将汇编指令例如“TRAP”放置在程序中--基本上是调用软件中断的汇编指令。
硬件执行这个TRAP汇编指令,首先将模式位从用户切换到内核,然后将代码指针设置为中断服务例程的开始位置。从此处开始,在内核模式下执行ISR,该ISR从堆栈中提取参数(这是可能的,因为内核可以访问任何内存位置,甚至是由用户进程拥有的内存位置),执行系统调用,并最终释放CPU,再次切换模式位,用户进程从离开的地方继续执行。
我的理解正确吗?
下面是我理解的简单图示: