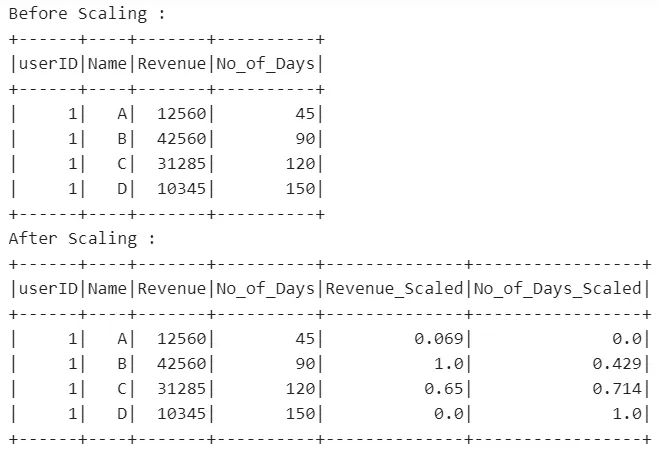
我正在尝试使用Python对SPARK DataFrame中的一列进行归一化处理。
我的数据集:
--------------------------
userID|Name|Revenue|No.of.Days|
--------------------------
1 A 12560 45
2 B 2312890 90
. . . .
. . . .
. . . .
--------------------------
在这个数据集中,除了userID和Name以外,我需要对Revenue和No.of Days进行归一化。
输出应该如下所示
userID|Name|Revenue|No.of.Days|
--------------------------
1 A 0.5 0.5
2 B 0.9 1
. . 1 0.4
. . 0.6 .
. . . .
--------------------------
用于计算或归一化每列值的公式为:
val = (ei-min)/(max-min)
ei = column value at i th position
min = min value in that column
max = max value in that column
我该如何使用PySpark轻松实现此操作?