更新:以下新增了3个更新
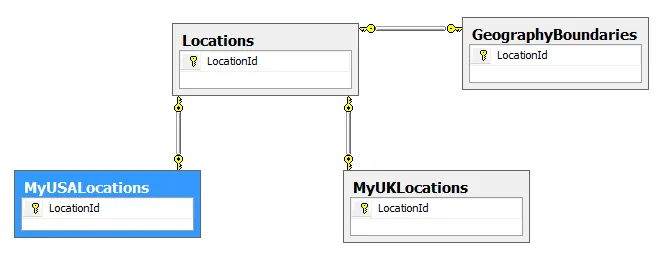
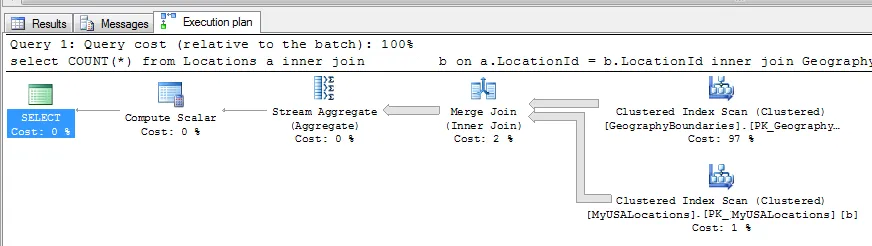
下面的SQL语句需要5分钟才能完成。我真的不理解 :( 第一个表中有6861534行,第二个表稍微少一些...第三个表(包含4个地理字段)与第一个表相同。
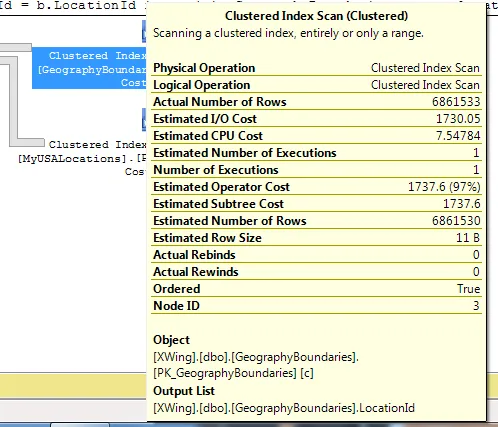
那些第三个表中的 GEOGRAPHY 字段... 它们不应该影响这个SQL语句... 是吗?难道是因为表太大(由于 GEOGRAPHY 字段),所以页面大小很大,破坏了COUNT执行的表扫描吗?
SELECT COUNT(*)
FROM [dbo].[Locations] a
inner join [dbo].[MyUSALocations] b on a.LocationId = b.LocationId
inner join [dbo].[GeographyBoundaries] c on a.locationid = c.LocationId
更新
根据要求,以下是有关GeographyBoundaries表的更多信息...
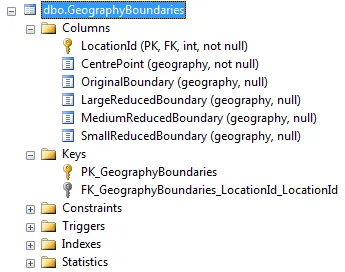
/****** Object: Index [PK_GeographyBoundaries] Script Date: 11/16/2010 12:42:36 ******/
ALTER TABLE [dbo].[GeographyBoundaries] ADD CONSTRAINT [PK_GeographyBoundaries] PRIMARY KEY CLUSTERED
(
[LocationId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
第二次更新 - 添加非聚集索引之后
添加非聚集索引之后,查询时间现在缩短到了4秒!这太棒了。但是为什么呢?
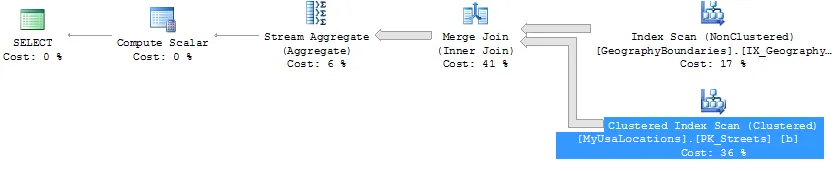
这是什么鬼?
第三次更新 - 更有趣更令人困惑的信息!
现在,当我只执行一次连接并强制使用索引时,查询时间又变成了5分钟。我这样做是为了:
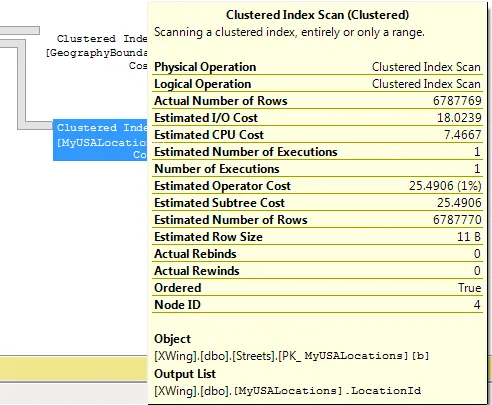
- 确保MyUSALocations表没有对连接造成影响。
- 确保主键没有出现异常情况。
.
SELECT COUNT(*)
FROM [dbo].[Locations] a
INNER JOIN [dbo].[GeographyBoundaries] c
WITH (INDEX(PK_GeographyBoundaries)) ON a.locationid = c.LocationId