学习算法时,我对计算时间复杂度有一点困惑。据我理解,如果算法的输出不依赖于输入大小,则需要常量时间,即O(1)。而当输出依赖于输入时,则称为线性时间,即O(n)。
但是,当我们知道输入大小时,时间复杂度如何计算呢?
例如,我有以下代码,它打印出1到100之间的所有质数。在这种情况下,我知道输入大小(100),那么时间复杂度会如何转化呢?
public void findPrime(){
for(int i = 2; i <=100; i++){
boolean isPrime = true;
for(int j = 2; j < i; j++){
int x = i % j;
if(x == 0)
isPrime = false;
}
if (isPrime)
System.out.println(i);
}
}
在这种情况下,由于时间是恒定的,复杂度仍然是O(1)吗?还是应该是O(n),其中n是影响两个循环的迭代次数的i条件?
另外,我说i的条件在运行时间方面对算法影响最大,这样说对吗?i越大,算法运行时间越长吗?
非常感谢您的帮助。
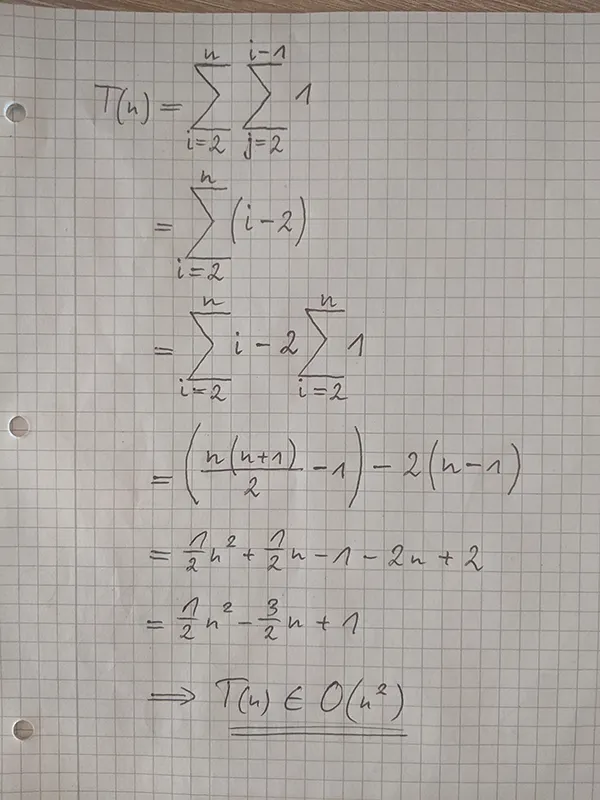
findPrime()接受一个参数 (findPrime(int max)) 并使用此参数 (i <= max)。 - MC Emperor