我是一名有用的助手,可以为您翻译文本。
我有一个(有点大的)平面文件(csv)。我试图使用SSIS包将其导入到我的SQL Server表中。没有什么特别的,只是简单的导入。问题是,超过50%的行是重复的。
例如,数据:
Item Number | Item Name | Update Date
ITEM-01 | First Item | 1-Jan-2013
ITEM-01 | First Item | 5-Jan-2013
ITEM-24 | Another Item | 12-Mar-2012
ITEM-24 | Another Item | 13-Mar-2012
ITEM-24 | Another Item | 14-Mar-2012
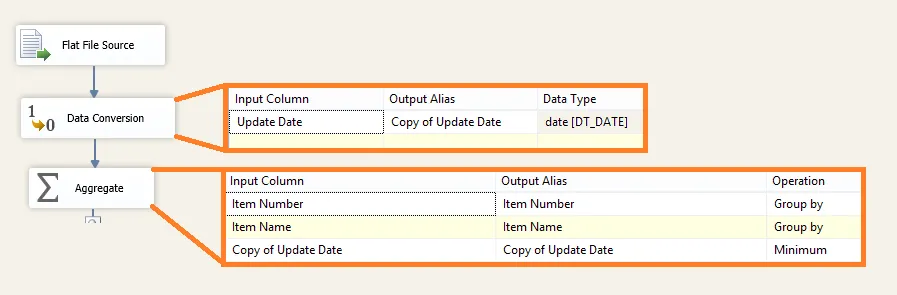
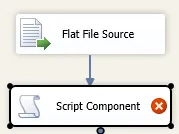
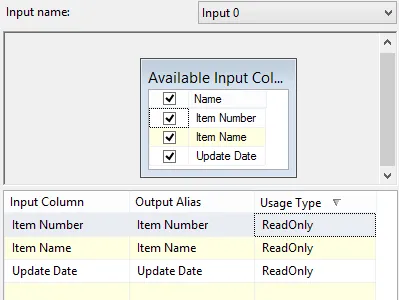
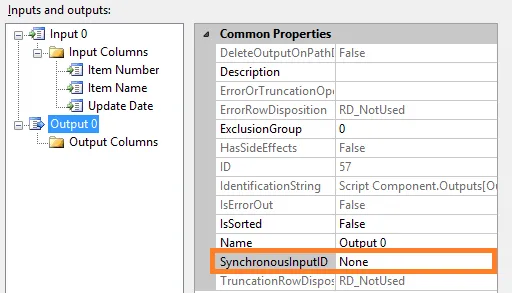
现在我需要使用这些数据创建我的主项目记录表,如您所见,由于更新日期的缘故,数据是重复的。保证文件始终按照项目编号进行排序。因此,我只需要检查如果下一个项目编号=上一个项目编号,则不导入此行。
我在SSIS包中使用了排序和删除重复项,但实际上它正在尝试对所有行进行排序,这是无用的,因为行已经排序。此外,这将花费很长时间来排序太多行。
那么还有其他方法吗?