什么是CUDA全局内存事务中的“coalesced”?即使阅读了我的CUDA指南,我仍然无法理解。如何做到这一点?在CUDA编程指南的矩阵示例中,按行访问矩阵称为“coalesced”,按列访问称为“coalesced”?
哪一个是正确的,为什么?
4个回答
190
这些信息可能仅适用于计算能力1.x或cuda 2.0。更新的架构和cuda 3.0具有更复杂的全局内存访问,实际上“合并的全局数据加载”甚至不会被为这些芯片进行分析。
此外,这种逻辑也可以应用于共享内存以避免银行冲突。
联合内存事务是半线程组中的所有线程同时访问全局内存的事务。这太过简单了,但正确的方法只是让连续的线程访问连续的内存地址。
因此,如果线程0、1、2和3读取全局内存地址0x0、0x4、0x8和0xc,则应该是一个合并的读取操作。
在矩阵的例子中,请记住要将矩阵线性地放置在内存中。您可以使用任何方式来完成此操作,并且您的内存访问应反映出矩阵的布局方式。因此,下面是一个3x4的矩阵示例:
0 1 2 3
4 5 6 7
8 9 a b
可以逐行完成,例如这样,使得(r,c)映射到内存(r * 4 + c)。
0 1 2 3 4 5 6 7 8 9 a b
假设你只需要访问一个元素,并且有四个线程,哪个线程将用于哪个元素?可能是其中之一:
thread 0: 0, 1, 2
thread 1: 3, 4, 5
thread 2: 6, 7, 8
thread 3: 9, a, b
thread 0: 0, 4, 8
thread 1: 1, 5, 9
thread 2: 2, 6, a
thread 3: 3, 7, b
哪个更好?哪一个会导致读取合并,哪一个不会?
无论哪种方式,每个线程都会进行三次访问。我们来看一下第一次访问,并查看线程是否连续访问内存。在第一种选项中,第一次访问是0、3、6、9。不连续,不合并。在第二种选项中,它是0、1、2、3。连续的!合并的!太棒了!
最好的方法可能是编写您的核函数,然后对其进行分析,以查看是否存在非合并的全局加载和存储。
- jmilloy
12
17
内存合并是一种技术,可以充分利用全局内存带宽。也就是说,当并行线程运行相同指令并访问全局内存中的连续位置时,最优访问模式被实现。
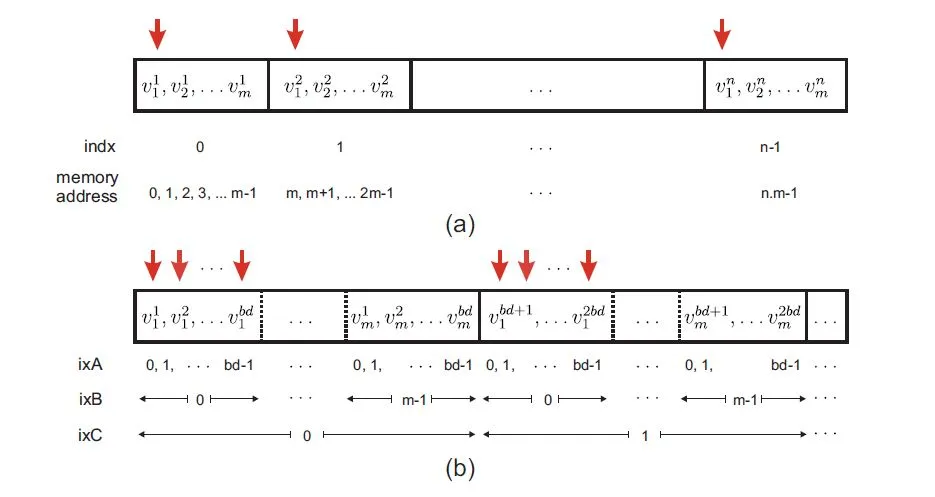
上图示例帮助解释了合并排列:
在(a)中,n个长度为m的向量以线性方式存储。向量j的元素i用v j i表示。每个GPU kernel中的线程都分配给一个m长度的向量。CUDA中的线程分组成块阵列,并且GPU中的每个线程都有一个唯一的ID,可以定义为indx=bd*bx+tx,其中bd表示块维度,bx表示块索引,tx是每个块中的线程索引。
垂直箭头演示了并行线程访问每个向量的第一个分量的情况,即内存的地址0、m、2m...如图(a)所示,此时内存访问不连续。通过将这些地址之间的空白部分归零(红色箭头在上图中显示),内存访问变得合并了。
但是,在这里问题变得有点棘手,因为每个GPU块允许驻留的线程数限制为bd。因此,可以通过按顺序存储前bd个向量的第一个元素来完成合并的数据排列,然后是第二个bd向量的第一个元素,依此类推。其余向量元素以类似的方式存储,如图(b)所示。如果n(向量数)不是bd的因数,则需要使用某些平凡值(例如0)填充最后一块中的剩余数据。
m × indx +i被寻址;在图(b)中,同样的组件在汇合存储模式下被寻址为(m × bd) ixC + bd × ixB + ixA,其中
ixC = floor[(m.indx + j )/(m.bd)]= bx,ixB = j,ixA = mod(indx,bd) = tx。总之,在存储大小为m的向量的示例中,线性索引映射到汇合索引如下:
m.indx +i −→ m.bd.bx +i .bd +tx
这种数据重新排列可以导致GPU全局内存的显着更高的内存带宽。
来源:“GPU‐based acceleration of computations in nonlinear finite element deformation analysis.”国际生物医学工程数值方法杂志(2013)。
- ramino
11
如果一个块中的线程正在访问连续的全局内存位置,则硬件将所有访问合并为单个请求(或者说是协同)。在矩阵示例中,行中的矩阵元素被线性地排列,其后是下一行,以此类推。例如,在一个2x2的矩阵和一个包含两个线程的块中,内存位置排列如下:
(0,0) (0,1) (1,0) (1,1)
对于行访问,线程1访问(0,0) 和 (1,0),这些访问无法合并。 对于列访问,线程1访问(0,0) 和 (0,1),这些访问可以合并,因为它们是相邻的。
(0,0) (0,1) (1,0) (1,1)
对于行访问,线程1访问(0,0) 和 (1,0),这些访问无法合并。 对于列访问,线程1访问(0,0) 和 (0,1),这些访问可以合并,因为它们是相邻的。
- penmatsa
1
11简洁明了,但请记住,“合并”(coalesced)不是指线程1连续进行两次访问,而是指线程1和线程2同时并行访问。以您的行访问示例为例,如果线程1访问(0,0)和(1,0),那么我假设线程2正在访问(0,1)和(1,1)。因此,第一次并行访问是1:(0,0)和2:(0,1) - > 合并! - jmilloy
4
合并的标准在CUDA 3.2 Programming Guide,G.3.2节中有详细记录。简而言之,warp中的线程必须按顺序访问内存,并且所访问的单词应≥32位。此外,warp访问的基地址应为64、128或256字节对齐,分别用于32、64和128位访问。
Tesla2和Fermi硬件可以比较好地合并8位和16位访问,但如果想要达到峰值带宽,则最好避免这些访问。
请注意,尽管Tesla2和Fermi硬件有所改进,但是合并绝不过时。即使在Tesla2或Fermi级别的硬件上,未能合并全局内存事务也可能导致性能下降2倍。(在启用ECC时,Fermi级别的硬件似乎只有连续但未合并的内存事务会受到20%的影响。)
Tesla2和Fermi硬件可以比较好地合并8位和16位访问,但如果想要达到峰值带宽,则最好避免这些访问。
请注意,尽管Tesla2和Fermi硬件有所改进,但是合并绝不过时。即使在Tesla2或Fermi级别的硬件上,未能合并全局内存事务也可能导致性能下降2倍。(在启用ECC时,Fermi级别的硬件似乎只有连续但未合并的内存事务会受到20%的影响。)
- ArchaeaSoftware
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
nvprof似乎也是一个强大的工具,可以为您提供帮助。我想强调的是,重要的指标取决于您的设备计算能力和 CUDA 版本,而nvprof应该允许您监视其中任何一个。首先让您的内核正常工作,然后再使用任何一个可用的分析器进行优化。 - jmilloy