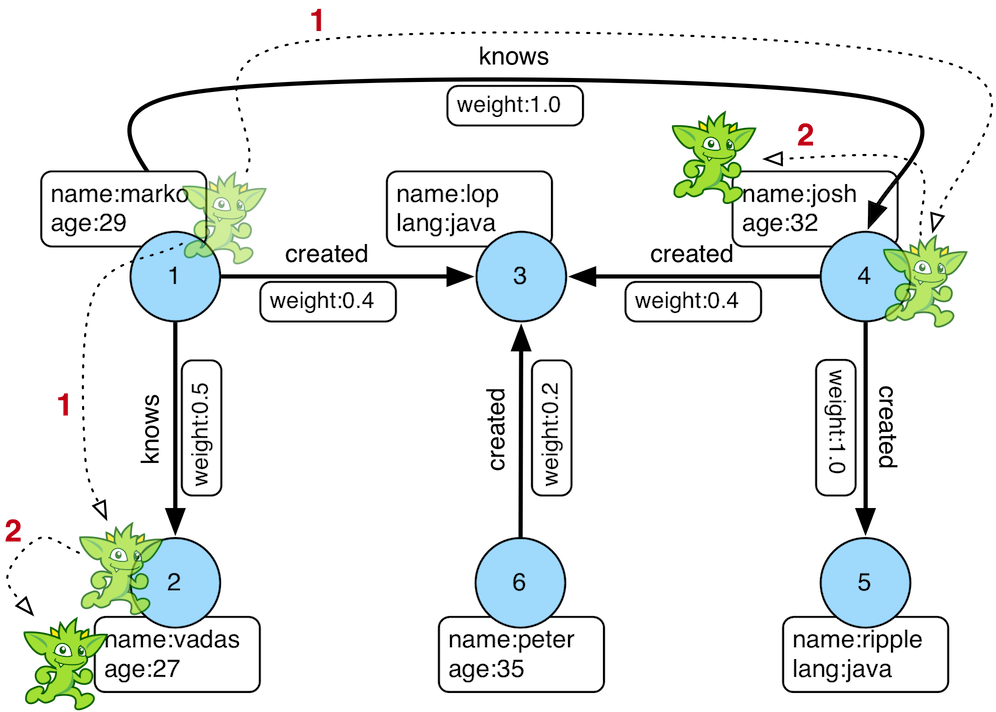
我正在使用 Neptune AWS,想要找出边的起始节点 ID 和结束节点 ID。对于 Neo4j,Map 步骤是可行的,但同样的查询在 Neptune 上无法工作。
数据示例:点击此处 查询内容:
数据示例:点击此处 查询内容:
{kind=link}
query = """g.V().hasLabel('Person').has("name", "marko").as("from", "to")
.repeat(bothE().as("e").otherV().as("to").as("to")).times(2).emit(hasLabel("Person")).hasLabel("Person").has("name", "josh")
.project("name", "Label","start", "end")
.by(select(all, "to").unfold().values("title").fold())
.by(select(all, "to").unfold().label().fold())
.by(select(all, "e").unfold().id().map{g.E(it.get()).next()}.outV().id().fold())
.by(select(all, "e").unfold().id().map{g.E(it.get()).next()}.inV().id().fold())
"""
这在Neptune上出现了错误,但在Neo4j上可以正常工作。是否有其他方法来获取起始节点和结束节点的ID?