有没有关于将这些图像转换成文本的建议?我正在使用pytesseract,在大多数情况下都运作良好,除了这个。理想情况下,我希望能准确读取这些数字。最坏的情况是我可以尝试使用PIL来确定'/'左边的数字是否为零。从左边开始找到第一个白色像素,然后...


from PIL import Image
from pytesseract import image_to_string
myText = image_to_string(Image.open("tmp/test.jpg"),config='-psm 10')
myText = image_to_string(Image.open("tmp/test.jpg"))
斜杠在中间会导致问题。我也尝试使用PIL的'.paste'在图像周围添加大量黑色。我可能还可以尝试一些其他的PIL技巧,但除非必须,否则我不想走这条路。
我尝试使用config='-psm 10',但我的8有时会变成“:”,而其他时候则是随机字符。我的0则变成了空白。
参考: pytesseract无法处理单个数字图像,用于 -psm 10
_____________编辑_______________ 附加样本:
 1BJ2I]
1BJ2I]
 DIS
DIS
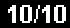 10.I'10
10.I'10
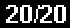 20.I20
20.I20
所以我正在进行一些巫术转换,目前似乎是有效的。但这看起来非常容易出错:
def ConvertPPTextToReadableNumbers(text):
text = RemoveNonASCIICharacters(text)
text = text.replace("I]", "0")
text = text.replace("|]", "0")
text = text.replace("l]", "0")
text = text.replace("B", "8")
text = text.replace("D", "0")
text = text.replace("S", "5")
text = text.replace(".I'", "/")
text = text.replace(".I", "/")
text = text.replace("I'", "/")
text = text.replace("J", "/")
return text
最终生成:
ConvertPPTextToReadableNumbers return text = 18/20
ConvertPPTextToReadableNumbers return text = 0/5
ConvertPPTextToReadableNumbers return text = 10/10
ConvertPPTextToReadableNumbers return text = 20/20