我们可以进行一些预处理来实现这个目标。假设我们有以下数据文件:
data.txt。
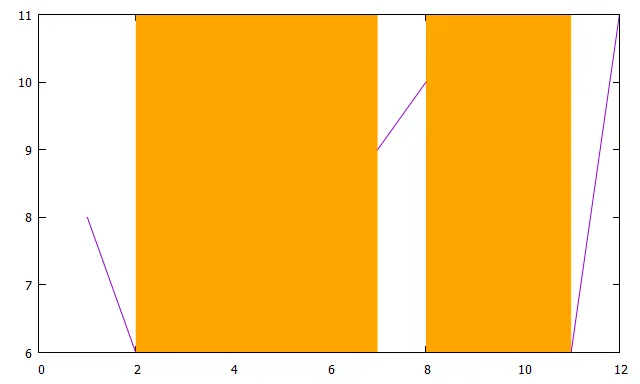
1 8
2 6
4 NaN
5 NaN
6 NaN
7 9
8 10
9 NaN
10 NaN
11 6
12 11
以下是使用Python 3编写的程序(当然,使用Python并不是唯一的方法),process.py1
data = [x.strip().split() for x in open("data.txt","r")]
i = 0
while i<len(data):
if (data[i][1]=="NaN"):
print(data[i-1][0],end=" ")
i+=1
while data[i][1]=="NaN": i+=1
print(data[i][0],end=" ")
else: i+=1
这个Python程序将读取数据文件,并针对每个NaN值范围输出上一个和下一个有效的x坐标。对于示例数据文件,它输出
2 7 8 11,可用作绘制矩形的边界。现在我们可以在gnuplot
2中进行操作。
breaks = system("process.py")
set for [i=0:words(breaks)/2-1] object (i+1) rectangle from word(breaks,2*i+1),graph 0 to word(breaks,2*i+2),graph 1 fillstyle solid noborder fc rgb "orange"
这将在此范围内绘制填充矩形。它确定断点变量中有多少个“块”(每组两个值),然后使用断点作为矩形的左右边界,每次读取两个值。
最后,绘制数据。
plot "data.txt" u 1:2 with lines
生成
显示填充矩形在NaN值范围内。
为了提供更多的实用性,以下awk程序process.awk3如果可用,就能够达到与上述Python程序相同的目的:
BEGIN {
started = 0;
last = "";
vals = "";
}
($2=="NaN") {
if (started==0) {
vals = vals " " last;
started = 1;
}
}
($2!="NaN") {
last = $1
if (started==1) {
vals = vals " " last;
started = 0;
}
}
END {
sub(/^ /,"",vals);
print vals;
}
我们可以通过将上面的系统调用替换为以下内容来使用它。
breaks = system("awk -f process.awk data.txt")
1 边界将被扩展到最后一个和下一个点,以完全填补间隙。 如果不需要这样做,则注释的值仅覆盖文件中 NaN 标识的区域(在示例情况中为 4-6 和 8-10)。 程序不会处理 NaN 值作为第一个或最后一个数据点。
2 我使用了实心橙色来表示间隙。 随意使用任何颜色规范。
3 awk 程序与 python 程序相同地扩展边界,但需要更多修改才能获得其他行为。 它具有与 python 相同的限制,无法处理 NaN 值作为第一个或最后一个数据点。
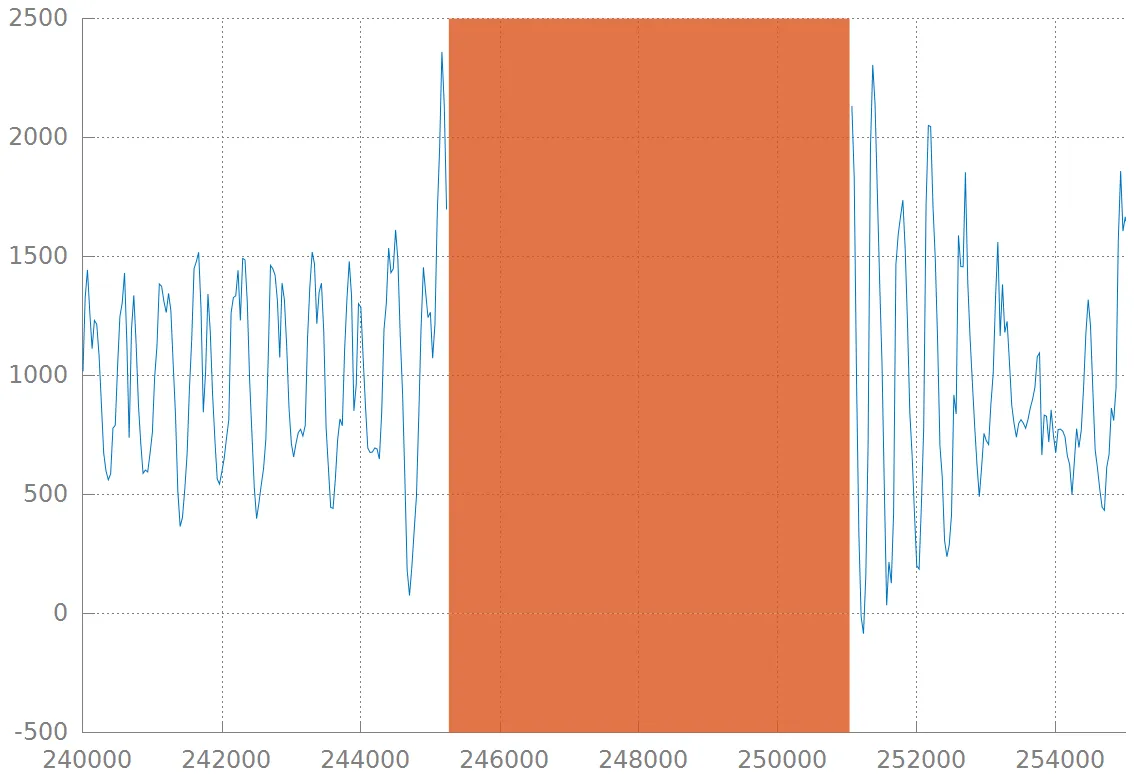
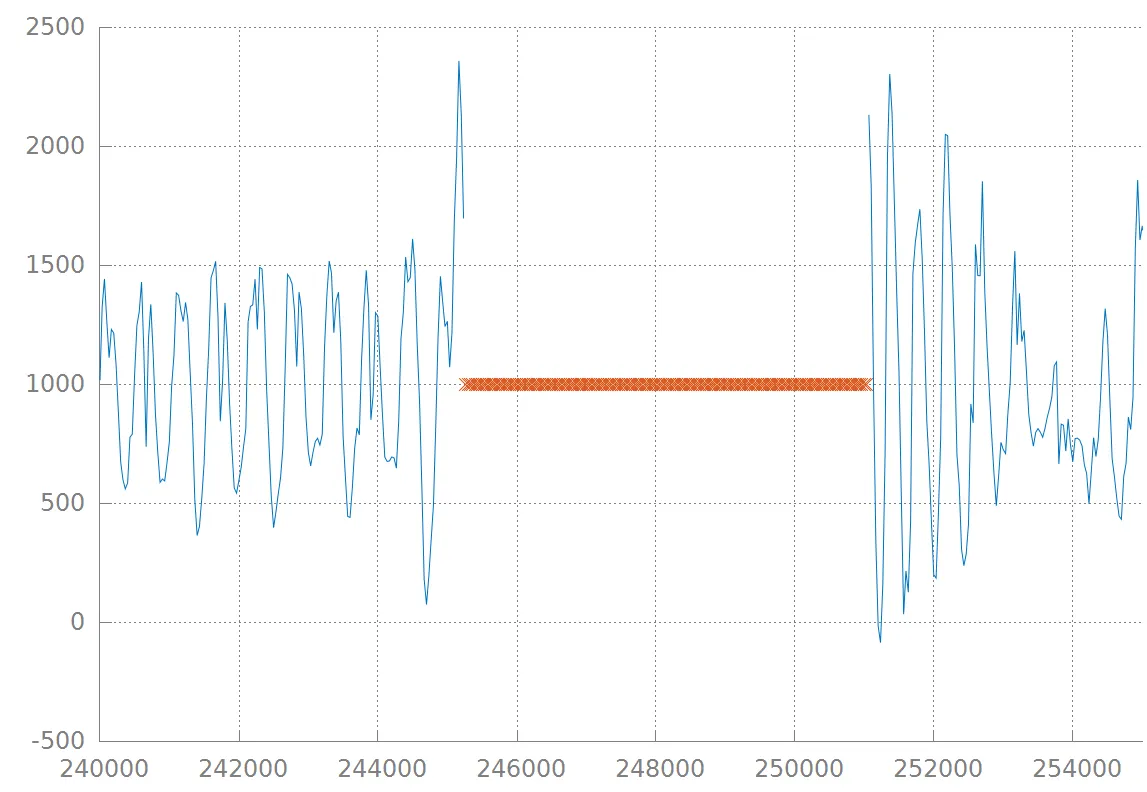 然而,这并不理想,因为 a) 我需要指定一个 y 值来绘制点,b) 这相当丑陋,特别是当数据集在时间上更长时。我想要的是像这样的东西:
然而,这并不理想,因为 a) 我需要指定一个 y 值来绘制点,b) 这相当丑陋,特别是当数据集在时间上更长时。我想要的是像这样的东西: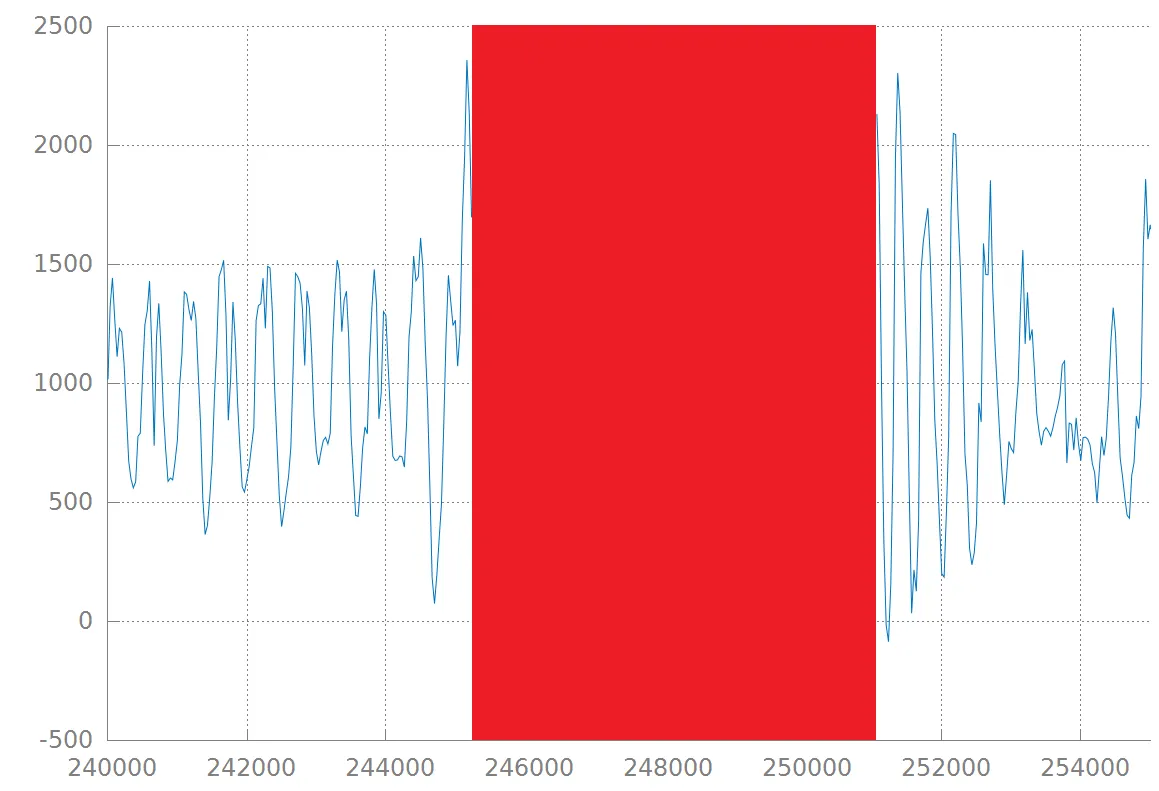 即,用一种颜色完全填充这个间隔(可能有一些透明度,与我的图片不同)。请注意,在这些示例中,只有一个缺失值间隔,但实际上可以在一个图中有任意数量的间隔。
即,用一种颜色完全填充这个间隔(可能有一些透明度,与我的图片不同)。请注意,在这些示例中,只有一个缺失值间隔,但实际上可以在一个图中有任意数量的间隔。