简要解释和解决方案
"(.*)" 正则表达式涉及很多回溯,因为它找到第一个 " 然后抓取整个字符串并向后回溯寻找距离字符串结尾最近的 "。由于您有一个更靠近开头的带引号子字符串,所以比使用 "(.*?)" 更需要回溯,因为这个 惰性 量词 *? 使正则表达式引擎在找到第一个 " 后寻找距离它最近的 "。
否定字符类解决方案 "([^"]*)" 是三种方法中最好的,因为它不必抓取 所有 字符,只需除了 " 之外的所有字符。然而,为了防止任何回溯并使表达式最终有效,您可以使用 占有量词。
如果您需要匹配像 " + no quotes here + " 这样的字符串,请使用:
"([^"]*+)"
在这种情况下,甚至不需要匹配尾引号:
"([^"]*+)
请看 正则表达式演示
事实上,我无法猜测我们如何用语言描述这个正则表达式。
后面的 "([^"]*+) 正则表达式可以描述为:
" - 从字符串左侧找到第一个 " 符号([^"]*+) - 匹配并捕获除了 " 以外的零个或多个符号,尽可能多地匹配,一旦引擎找到一个双引号,匹配就会立即返回,不会回溯。
量词
更多关于 Rexegg.com 上的量词 的信息:
A*表示零个或多个A,尽可能多的匹配(贪婪),如果引擎需要回溯,则放弃字符(顺从)
A*?表示零个或多个A,尽可能少的匹配以使整体模式匹配(懒惰)
A*+表示零个或多个A,尽可能多的匹配(贪婪),如果引擎尝试回溯,则不放弃字符(占有)
如您所见,?并不是一个独立的量词,它是另一个量词的一部分。
我建议了解更多关于为什么懒惰量词很耗费资源以及否定类解决方案真正安全快速地处理输入字符串(在其中只匹配引号后面的非引号字符,然后是最终引号)。
.*?、.*和[^"]*+量词之间的区别
贪心算法
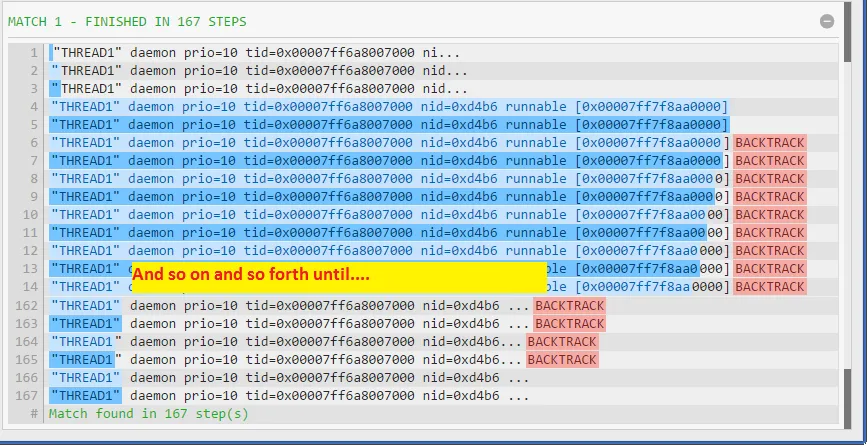
"(.*)" 的解决方案工作流程如下:从左到右检查每个符号,寻找
",一旦找到,它会抓取整个字符串直到结束,并检查每个符号是否等于
"。因此,在您的输入字符串中,它会回溯160次。
Lazy
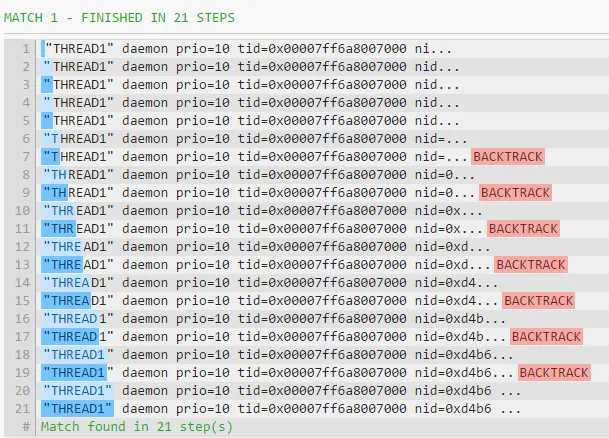
"(.*?)" 解决方案的工作方式如下:引擎找到第一个
",然后在模式中前进并尝试下一个标记(即
")与
THREAD1 中的
T 匹配。这失败了,因此引擎回溯并允许
.*? 扩展其匹配项,使其匹配
T。再次,引擎在模式中前进。现在它尝试将
" 与
THREAD1 中的
H 匹配。这也失败了,因此引擎回溯并允许
.*? 扩展并匹配
H。
然后该过程重复进行——引擎前进、失败、回溯、允许惰性的 .*? 扩展其匹配项、前进、失败等等。对于每个由 .*? 匹配的字符,引擎都必须回溯。从计算的角度来看,这种匹配一项、前进、失败、回溯、扩展的过程是“昂贵”的。
由于下一个
"不远,因此回溯步骤的数量比贪婪匹配要少得多。
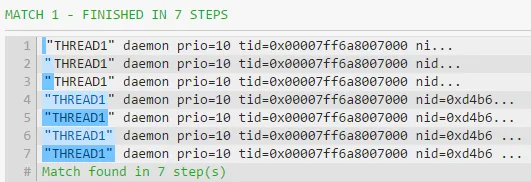
- 使用否定字符类的占有量词解决方案
"([^"]*+)" 的工作原理如下: 引擎找到最左边的 ",然后获取所有不是 " 直到第一个 " 的字符。否定字符类[^"]*+ 贪婪地匹配零个或多个不是双引号的字符。因此,我们保证点星(dot-star)永远不会跳过第一个遇到的 "。这是一种更直接和高效的在某些分隔符之间进行匹配的方法。请注意,在这种解决方案中,我们可以完全信任量化 [^"] 的 *。即使它是贪婪的,也没有风险让 [^"] 匹配太多,因为它与 " 互斥。这是正则表达式风格指南中对比原则的体现[见来源]。
请注意,所有权量词不允许正则表达式引擎回溯到子表达式中,一旦匹配成功,
"之间的符号将成为一个硬块,由于正则表达式引擎遇到的某些“不便”,它将无法重新排序此文本块中的任何字符。
对于当前表达式,这并没有太大的区别。
.*?,这将使搜索变得懒惰。我认为你当前的正则表达式有一个缺陷。如果在线程名称后面有一个“some text here”,那么最后一个"将被映射。 - TheLostMind"",那怎么办?线程名从字符串的开头开始,回溯值得吗? - TheLostMind"([^"]*+)"жҳҜеҢ№й…Қзұ»дјјдәҺ"no-quotes-here"иҝҷж ·зҡ„еӯ—з¬ҰдёІзҡ„жңҖдҪійҖүжӢ©гҖӮ - Wiktor Stribiżew