如何编写 for 循环或列表推导式,以便每个迭代返回两个元素?
l = [1,2,3,4,5,6]
for i,k in ???:
print str(i), '+', str(k), '=', str(i+k)
输出:
1+2=3
3+4=7
5+6=11
pairwise()(或grouped())的实现。def pairwise(iterable):
"s -> (s0, s1), (s2, s3), (s4, s5), ..."
a = iter(iterable)
return zip(a, a)
for x, y in pairwise(l):
print("%d + %d = %d" % (x, y, x + y))
或者,更普遍地说:
def grouped(iterable, n):
"s -> (s0,s1,s2,...sn-1), (sn,sn+1,sn+2,...s2n-1), (s2n,s2n+1,s2n+2,...s3n-1), ..."
return zip(*[iter(iterable)]*n)
for x, y in grouped(l, 2):
print("%d + %d = %d" % (x, y, x + y))
izip作为Python 3内置的zip()函数的替代品。itertools documentation中的pairwise recipe混淆,后者产生s -> (s0, s1), (s1, s2), (s2, s3), ...,如评论中@lazyr所指出的那样。
对于那些想在Python 3上使用mypy进行类型检查的人,这里有一个小补充:
from typing import Iterable, Tuple, TypeVar
T = TypeVar("T")
def grouped(iterable: Iterable[T], n=2) -> Iterable[Tuple[T, ...]]:
"""s -> (s0,s1,s2,...sn-1), (sn,sn+1,sn+2,...s2n-1), ..."""
return zip(*[iter(iterable)] * n)
itertools配方函数相比,您的版本仅产生一半数量的对。当然,你的更快... - Sven Marnach- egafni[(1, 2)] ..而您期望得到的是[(1,2),(3,)]。
izip_longest()代替izip()。例如:list(izip_longest(*[iter([1, 2, 3])]*2, fillvalue=0)) --> [(1, 2), (3, 0)]。希望这可以帮到您。 - johnsyweb你需要一个包含两个元素的元组,因此
data = [1,2,3,4,5,6]
for i,k in zip(data[0::2], data[1::2]):
print str(i), '+', str(k), '=', str(i+k)
其中:
data[0::2] 表示创建由索引为偶数的元素组成的子集合集合。zip(x,y) 从 x 和 y 两个集合中,将相同索引位置的元素打包成元组(tuple)的集合。for i, j, k in zip(data[0::3], data[1::3], data[2::3]): - lifebalanceitertools.islice 来拯救:for i,k in zip(islice(data, 0, None, 2), islice(data, 1, None, 2):。如果你担心“不迭代可迭代对象的最后元素”,可以将 zip 替换为 itertools.zip_longest 并使用一个对你有意义的 fillvalue。 - Escape0707s -> (s0, s1), (s1, s2), (s2, s3), ...,并使用以下代码实现:for i,k in zip(data[0::1], data[1::1]): - Kapil Marwaha>>> l = [1,2,3,4,5,6]
>>> zip(l,l[1:])
[(1, 2), (2, 3), (3, 4), (4, 5), (5, 6)]
>>> zip(l,l[1:])[::2]
[(1, 2), (3, 4), (5, 6)]
>>> [a+b for a,b in zip(l,l[1:])[::2]]
[3, 7, 11]
>>> ["%d + %d = %d" % (a,b,a+b) for a,b in zip(l,l[1:])[::2]]
['1 + 2 = 3', '3 + 4 = 7', '5 + 6 = 11']
zip函数返回一个不可下标访问的zip对象。需要先将其转换为序列(例如list、tuple等),但是说“不起作用”可能有些过分。 - vaultahzip 对象转换为元组列表,如下所示:output = list(zip_object)。 - Rob Irwinl = [1, 2, 3, 4, 5, 6]一个简单的解决方案。
for i in range(0, len(l), 2): print str(l[i]), '+', str(l[i + 1]), '=', str(l[i] + l[i + 1])
((l[i], l[i+1])for i in range(0, len(l), 2)),并且可以轻松地修改为更长的元组。 - Basel Shishani虽然使用zip的所有答案都是正确的,但我发现自己实现这个功能可以让代码更易读:
def pairwise(it):
it = iter(it)
while True:
try:
yield next(it), next(it)
except StopIteration:
# no more elements in the iterator
return
it = iter(it) 这部分代码确保 it 是一个迭代器而不仅仅是一个可迭代对象。如果 it 已经是迭代器,那么这行代码就没有任何作用。
使用方法:
for a, b in pairwise([0, 1, 2, 3, 4, 5]):
print(a + b)
it 只是一个迭代器而不是可迭代对象,此解决方案同样适用。其他解决方案似乎依赖于在序列中创建两个独立的迭代器的可能性。 - skyking我希望这将是更加优雅的做法。
a = [1,2,3,4,5,6]
zip(a[::2], a[1::2])
[(1, 2), (3, 4), (5, 6)]
from itertools import zip_longest。它将返回 [(1, 2), (3, 4), (5, 6), (7, None)]。 - egvosimple_benchmark),比较了各种解决方案的性能,并包括来自我的软件包之一的函数:iteration_utilities.grouper。from iteration_utilities import grouper
import matplotlib as mpl
from simple_benchmark import BenchmarkBuilder
bench = BenchmarkBuilder()
@bench.add_function()
def Johnsyweb(l):
def pairwise(iterable):
"s -> (s0, s1), (s2, s3), (s4, s5), ..."
a = iter(iterable)
return zip(a, a)
for x, y in pairwise(l):
pass
@bench.add_function()
def Margus(data):
for i, k in zip(data[0::2], data[1::2]):
pass
@bench.add_function()
def pyanon(l):
list(zip(l,l[1:]))[::2]
@bench.add_function()
def taskinoor(l):
for i in range(0, len(l), 2):
l[i], l[i+1]
@bench.add_function()
def mic_e(it):
def pairwise(it):
it = iter(it)
while True:
try:
yield next(it), next(it)
except StopIteration:
return
for a, b in pairwise(it):
pass
@bench.add_function()
def MSeifert(it):
for item1, item2 in grouper(it, 2):
pass
bench.use_random_lists_as_arguments(sizes=[2**i for i in range(1, 20)])
benchmark_result = bench.run()
mpl.rcParams['figure.figsize'] = (8, 10)
benchmark_result.plot_both(relative_to=MSeifert)
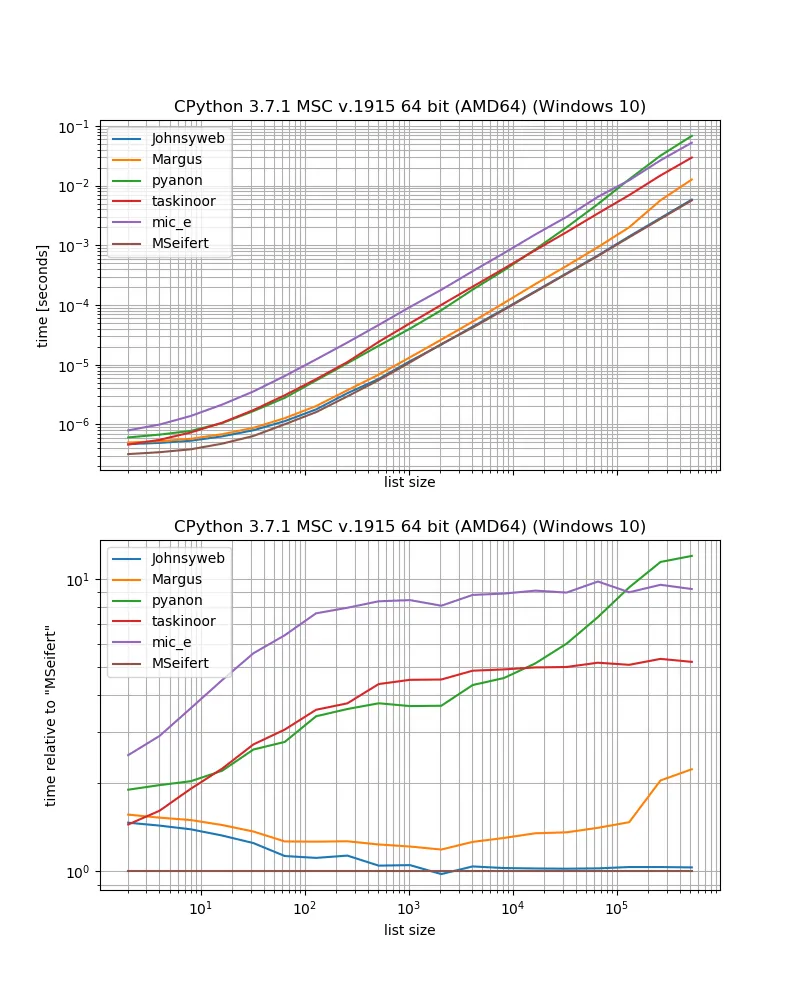
因此,如果您想要没有外部依赖项的最快解决方案,您可能应该只使用Johnysweb提供的方法(在撰写本文时,它是得票最高和被接受的答案)。
如果您不介意额外的依赖性,则来自iteration_utilities的grouper可能会更快一些。
一些方法具有一些限制,在这里尚未讨论。
例如,一些解决方案仅适用于序列(即列表、字符串等),例如使用索引的Margus/pyanon/taskinoor解决方案,而其他解决方案适用于任何可迭代对象(即序列和生成器、迭代器),如Johnysweb/mic_e/my解决方案。
然后,Johnysweb还提供了一种适用于除2以外的其他大小的解决方案,而其他答案则没有(好吧,iteration_utilities.grouper也允许设置要“组合”的元素数量)。
还有一个问题,即如果列表中有奇数个元素,应该发生什么。应该忽略剩余的项目吗?应该填充列表以使其大小相同吗?应该将剩余的项目作为单个返回?其他答案没有直接解决这一点,但是如果我没有忽略任何内容,它们都遵循了忽略剩余项的方法(除了taskinoors答案-它实际上会引发异常)。
使用grouper,您可以决定要做什么:
>>> from iteration_utilities import grouper
>>> list(grouper([1, 2, 3], 2)) # as single
[(1, 2), (3,)]
>>> list(grouper([1, 2, 3], 2, truncate=True)) # ignored
[(1, 2)]
>>> list(grouper([1, 2, 3], 2, fillvalue=None)) # padded
[(1, 2), (3, None)]
同时使用zip和iter命令:
我认为使用iter的这种解决方案相当优雅:
it = iter(l)
list(zip(it, it))
# [(1, 2), (3, 4), (5, 6)]
我在 Python 3 zip 文档 中找到了它。
it = iter(l)
print(*(f'{u} + {v} = {u+v}' for u, v in zip(it, it)), sep='\n')
# 1 + 2 = 3
# 3 + 4 = 7
# 5 + 6 = 11
为了将其推广到每次处理 N 个元素:
N = 2
list(zip(*([iter(l)] * N)))
# [(1, 2), (3, 4), (5, 6)]
for (i, k) in zip(l[::2], l[1::2]):
print i, "+", k, "=", i+k
zip(*iterable)函数返回一个元组,其中包含每个可迭代对象的下一个元素。
l[::2] 返回列表中第1、第3、第5等元素:第一个冒号表示切片从开始处开始,因为后面没有数字,第二个冒号仅在需要“切片步长”(在本例中为2)时才需要。
l[1::2] 做同样的事情,但是从列表的第二个元素开始,因此它返回原始列表的第2、第4、第6等元素。[number::number] 语法的工作原理。对于不经常使用 Python 的人很有帮助。通过解包:
l = [1,2,3,4,5,6]
while l:
i, k, *l = l
print(f'{i}+{k}={i+k}')
l,之后将其清空。
for i, k in zip(_x := iter(mylist), _x): ...- Alex Just Alex