一种快速查看数据库中信息的好方法是应用一个自动创建所有表格和它们之间关系的数据库图的工具。根据我的经验,这样的工具使用外键作为关系,而我尝试的大多数数据库都不包含外键。它们确实满足与外键对应的约束条件,但不会强制执行它们。然后我会得到一个由一堆无关的表格组成的“图表”。因此,我正在寻找能够计算“未声明的外键”的软件,并且可以将其用作数据库图中的表格关系,或者生成相应的外键声明的SQL代码。您知道有什么工具可以做到这一点吗?最好是免费的。
在数据库中发现事实上的外键的工具?
8
- reinierpost
8
1这样的工具需要做出什么样的假设才能计算这些未声明的外键呢?显式的外键作为元数据描述了表之间的关系。你是否认为该工具会通过引用列和被引用表之间的命名约定来纯粹地检测关系? - greghmerrill
首先要做的是列出包含依赖关系;目前,我的脚本首先列出所有候选主键列(具有唯一值的列),然后尝试将数据库中的每个列回显与这些列进行比较,以检查第一个值是否都包含在第二个值中,但这可以进行优化 - 参见例如http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.67.7484&rep=rep1&type=pdf。 - reinierpost
这个主要问题是假阳性:许多表都有自动编号的ID,所以当候选主键中的值较少时,它们经常会在不相关的键中产生包含关系。因此需要进行一定程度的可配置性或后处理来筛除这些情况。 - reinierpost
@Mytskine:你愿意分享你的修改吗?我的脚本也是用Perl编写的,基于DBI,也许我们可以共享一下我们的努力。 - reinierpost
这是一个接近重复的问题,链接为https://dev59.com/J0XRa4cB1Zd3GeqPqUMN。 - reinierpost
显示剩余3条评论
4个回答
6
有趣的问题。您希望解析数据库架构和数据,确定哪些表是相关的或应该相互关联,而没有任何严格的关系定义。实际上,您正在尝试推断关系。
我认为您可以通过两种方式推断这样的关系。首先,让我说一下,您的方法可能会因您使用的数据库而有所不同。有许多问题值得思考(我不需要答案,但值得反思)
- 这些是遵循某些一致命名惯例或模式的企业内部系统吗? - 还是它们是随时随地都能遇到的“野生”数据库? - 您准备做出什么样的假设? - 您更喜欢在结果中获得更多的误报还是漏报?
请注意,这种类型的推断几乎肯定会产生错误的结果,并且建立在许多假设之上。
因此,我提供了两种方法,我将同时使用它们。
通过结构/命名(符号分析)推断关系
常见的数据库设计是将主键列命名为表名(例如,在表“Customer”上为“CustomerId”),或者简单地将主键列命名为“Id”。
具有对另一个表的FK关系的表通常将其相关列命名为与相关表相同。在“Order”表中,我期望有一个“CustomerId”列,它引用“Customer”表中的“CustomerId”/“Id”列。
此类分析将包括
- 检查跨表的列以查找相似短语/单词 - 查找与其他表名称相似的列名 - 检查包含其他列名称的列名(例如,“FirstCustomerId”和“SecondCustomerId”都指向“Customer”表中的“CustomerId”列)
通过数据(统计分析)推断关系
像您在评论中建议的那样查看数据将允许您确定“可能”的引用。如果“Order”表中的“CustomerId”列包含不存在于“Customer”表的“Id”列中的值,则合理怀疑这是有效的关系(尽管您永远不知道!)
一种简单的数据分析形式是使用日期和时间。创建时间接近的行更有可能彼此相关。如果对于每个创建的“Order”行,还存在在几秒钟内创建的2到5个“Item”行,则两者之间存在关系。
更详细的分析可以关注所用值的范围和分布。
例如,如果你的
如果你对现有数据库执行数据分析以收集“真实数据”,我期望能得到一些可用来指导结构推断的模式。当一个具有大量记录的表具有一个重复多次的小值数目的列(不一定需要按顺序),则更可能这一列与具有相应小行数的表相关。 总之 祝你好运。这是一个有趣的问题,我只是提出了一些想法,但这非常取决于试验、数据收集和性能调整的情况。
我认为您可以通过两种方式推断这样的关系。首先,让我说一下,您的方法可能会因您使用的数据库而有所不同。有许多问题值得思考(我不需要答案,但值得反思)
- 这些是遵循某些一致命名惯例或模式的企业内部系统吗? - 还是它们是随时随地都能遇到的“野生”数据库? - 您准备做出什么样的假设? - 您更喜欢在结果中获得更多的误报还是漏报?
请注意,这种类型的推断几乎肯定会产生错误的结果,并且建立在许多假设之上。
因此,我提供了两种方法,我将同时使用它们。
通过结构/命名(符号分析)推断关系
常见的数据库设计是将主键列命名为表名(例如,在表“Customer”上为“CustomerId”),或者简单地将主键列命名为“Id”。
具有对另一个表的FK关系的表通常将其相关列命名为与相关表相同。在“Order”表中,我期望有一个“CustomerId”列,它引用“Customer”表中的“CustomerId”/“Id”列。
此类分析将包括
- 检查跨表的列以查找相似短语/单词 - 查找与其他表名称相似的列名 - 检查包含其他列名称的列名(例如,“FirstCustomerId”和“SecondCustomerId”都指向“Customer”表中的“CustomerId”列)
通过数据(统计分析)推断关系
像您在评论中建议的那样查看数据将允许您确定“可能”的引用。如果“Order”表中的“CustomerId”列包含不存在于“Customer”表的“Id”列中的值,则合理怀疑这是有效的关系(尽管您永远不知道!)
一种简单的数据分析形式是使用日期和时间。创建时间接近的行更有可能彼此相关。如果对于每个创建的“Order”行,还存在在几秒钟内创建的2到5个“Item”行,则两者之间存在关系。
更详细的分析可以关注所用值的范围和分布。
例如,如果你的
Order表有一个St_Id列 - 你可能会通过符号分析推断该列很可能与State表或Status表相关。 St_Id列有6个离散值,并且90%的记录由2个值覆盖。 State表有200行,Status表有9行。你可以合理地推断St_Id列与Status表相关 - 它给出了更大的表行覆盖率(表中的2/3行被“使用”,而State表中只有3%的行将被使用)。如果你对现有数据库执行数据分析以收集“真实数据”,我期望能得到一些可用来指导结构推断的模式。当一个具有大量记录的表具有一个重复多次的小值数目的列(不一定需要按顺序),则更可能这一列与具有相应小行数的表相关。 总之 祝你好运。这是一个有趣的问题,我只是提出了一些想法,但这非常取决于试验、数据收集和性能调整的情况。
- Kirk Broadhurst
2
感谢您详细的回复。我非常喜欢您如何解决一个比我原来尝试表述的更为通用的问题,我有时可能需要解决这样一个更为通用的问题。在寻找严格的外键时,我只需寻找包含依赖项,如果我将自己限制在单列依赖项,则数据库大小仅为二次方,对于我的用例而言,这意味着我可以计算它们,而不必以某种方式近似解决方案。 - reinierpost
然而,对于较大的数据库,在实践中进行详尽的包含依赖性检查是不切实际的。因此,基于符号和统计分析的实现可以在 https://github.com/janmotl/linkifier 上找到。 - user824276
5
这在大多数情况下都是个不容易解决的任务。如果你很幸运地分析到现代框架(如Ruby on Rails、CakePHP),并且开发人员严格遵循列约定,那么你有一个合理的机会找到许多,但不是所有的暗示关系。
也就是说,如果你的表使用像user_id这样的列来引用users表中的条目。
请注意:一些实体名称可能会存在不规则的复数形式(例如:entity变为entities,而不是entitys),这些比较难以捕捉(但仍然可以)。然而,像admin_id这样的键与用户表上的user.id连接,不能推断出它们之间的关系。这些情况需要手动处理。
你没有指定RDBMS,但我经常使用MySQL,并且目前正在处理这个问题。
以下MySQL脚本将推断出由列名所暗示的大多数关系。然后,它会列出任何它找不到表名的关系,以便你至少知道你缺少哪些关系。其中包括父子关系、单数和复数名称,以及暗示的关系:
-- this DB is where MySQL keeps schema information
use information_schema;
-- change this to the DB you want to analyse
set @db_name = "example_DB";
-- infer relationships
-- NB: this won't catch names that pluralise irregularly like category -> categories or bus_id -> buses etc.
select LEFT(COLUMN_NAME, CHAR_LENGTH(COLUMN_NAME) - 3 ) as inferred_parent_singular
, CONCAT(LEFT(COLUMN_NAME, CHAR_LENGTH(COLUMN_NAME) - 3 ),"s") as inferred_parent_plural
, C.TABLE_NAME as child_table
, CONCAT(LEFT(COLUMN_NAME, CHAR_LENGTH(COLUMN_NAME)-3), "s has many ", C.TABLE_NAME) as inferred_relationship
from COLUMNS C
JOIN TABLES T on C.TABLE_NAME = T.TABLE_NAME
and C.TABLE_SCHEMA = T.TABLE_SCHEMA
and T.TABLE_TYPE != "VIEW" -- filter out views; comment this line if you want to include them
where COLUMN_NAME like "%_id" -- look for columns of the form <name>_id
and C.TABLE_SCHEMA = T.TABLE_SCHEMA and T.TABLE_SCHEMA = @db_name
-- and C.TABLE_NAME not like "wwp%" -- uncomment and set a pattern to filter out any tables you DON'T want included, e.g. wordpress tables e.g. wordpress tables
-- finally make sure to filter out any inferred names that aren't really tables
and CONCAT(LEFT(COLUMN_NAME, CHAR_LENGTH(COLUMN_NAME) - 3 ),"s") -- this is the inferred_parent_plural, but can't use column aliases in the where clause sadly
in (select TABLE_NAME from TABLES where TABLE_SCHEMA = @db_name)
;
这将返回如下结果:
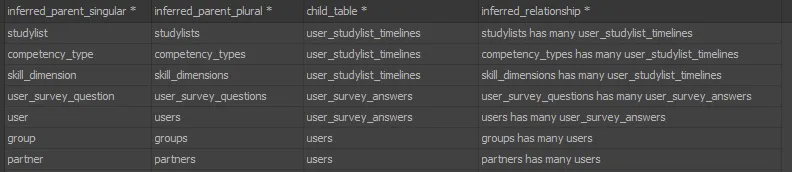 然后,您可以使用以下命令检查检测到的任何命名约定异常:
然后,您可以使用以下命令检查检测到的任何命名约定异常:-- Now list any inferred parents that weren't real tables to see see why (irregular plurals and columns not named according to convention)
select LEFT(COLUMN_NAME, CHAR_LENGTH(COLUMN_NAME) - 3 ) as inferred_parent_singular
, CONCAT(LEFT(COLUMN_NAME, CHAR_LENGTH(COLUMN_NAME) - 3 ),"s") as inferred_parent_plural
, C.TABLE_NAME as child_table
from COLUMNS C
JOIN TABLES T on C.TABLE_NAME = T.TABLE_NAME
and C.TABLE_SCHEMA = T.TABLE_SCHEMA
and T.TABLE_TYPE != "VIEW" -- filter out views, comment this line if you want to include them
where COLUMN_NAME like "%_id"
and C.TABLE_SCHEMA = T.TABLE_SCHEMA and T.TABLE_SCHEMA = @db_name
-- and C.TABLE_NAME not like "wwp%" -- uncomment and set a pattern to filter out any tables you DON'T want included, e.g. wordpress tables e.g. wordpress tables
-- this time only include inferred names that aren't real tables
and CONCAT(LEFT(COLUMN_NAME, CHAR_LENGTH(COLUMN_NAME) - 3 ),"s")
not in (select TABLE_NAME from TABLES where TABLE_SCHEMA = @db_name)
;
这将返回如下结果,您可以手动处理:
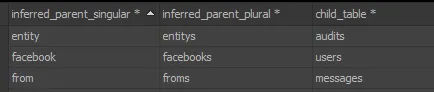 您可以修改这些脚本以输出对您有用的任何内容,包括外键创建语句(如果需要)。在这里,最后一列是一个简单的“具有多个”关系语句。我在一个名为pidgin的工具中使用它,该工具是一种快速建模工具,根据使用非常简单的语法(称为“pidgin”)编写的关系语句即时绘制关系图。您可以在http://pidgin.gruffdavies.com上查看它。
您可以修改这些脚本以输出对您有用的任何内容,包括外键创建语句(如果需要)。在这里,最后一列是一个简单的“具有多个”关系语句。我在一个名为pidgin的工具中使用它,该工具是一种快速建模工具,根据使用非常简单的语法(称为“pidgin”)编写的关系语句即时绘制关系图。您可以在http://pidgin.gruffdavies.com上查看它。我已经在演示数据库上运行了上面的脚本,以展示您可以期望的结果类型:
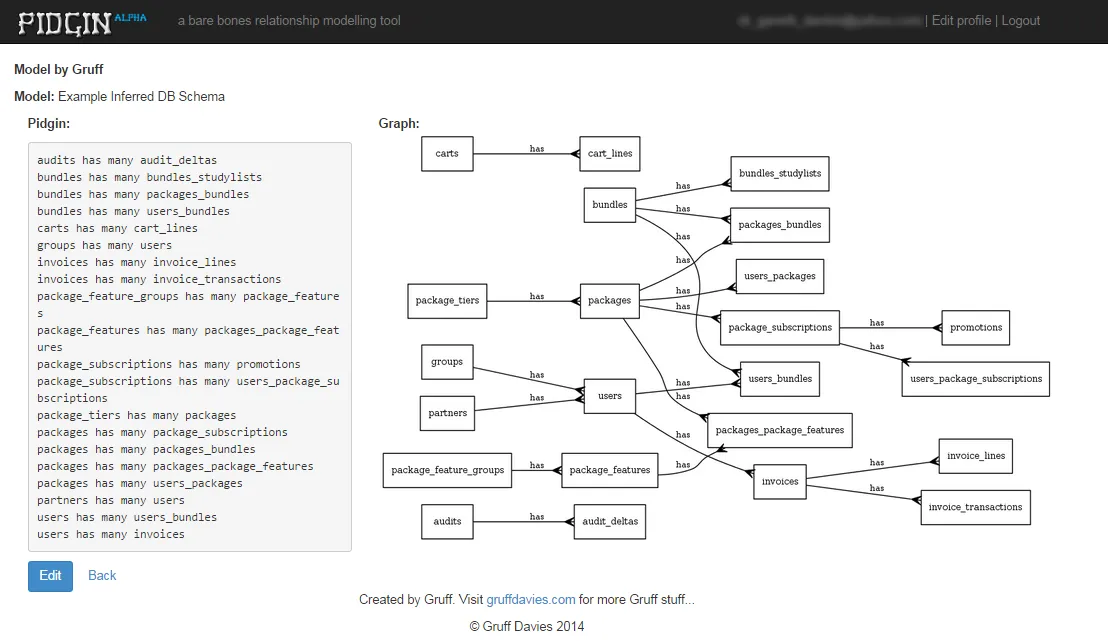 我没有在我的脚本中考虑不规则的复数形式,但我可能会尝试一下,至少对于以-y结尾的实体而言。如果您想自己尝试,请编写一个存储函数,将
我没有在我的脚本中考虑不规则的复数形式,但我可能会尝试一下,至少对于以-y结尾的实体而言。如果您想自己尝试,请编写一个存储函数,将<name>_id列名作为参数,去除_id部分,然后应用一些启发式方法来尝试正确地形成复数。希望这对您有所帮助!
- Gruff
5
这显然很有用,而且与我的方法互补,我的方法根本不考虑列名,只考虑列值集合:它检查一个是否包括另一个,并允许用户强制实施最小大小。因此,你可以将其添加到你的工具中。 - reinierpost
所以你正在对数据进行集合分析来推断关系?听起来很有趣(但计算成本高吗?)。最终,我决定将启发式算法留给一个 Ruby 脚本,将其构建到工具中,因此使用我的新方法,您只需要提供表格列表和列列表,它就会完成剩下的工作,并报告异常,然后您进行更正。效果非常好! - Gruff
1其实并不难:SQL可以表达这样的测试。如果脚本不那么丑陋,我会公开发布它;原则很简单。 - reinierpost
当然,表达集合成员很容易,这是SQL的整个基础,但我想知道它们在非常大的集合和数百个键上的性能如何? - Gruff
很难说。到目前为止,我还没有在任何大型项目中使用它,当然这取决于索引是否存在。(我曾经做过一个项目,将Web服务器日志导入SQLite以进行分析查询,但在执行任何连接之前,我必须添加索引。此脚本不会添加任何索引。) - reinierpost
1
以下产品都声称具备外键发现能力:
ERwin http://www.ascent.co.za/products/ca_erwin_data_profiler.html
并且 XCaseForI http://xcasefori.com/discovering/index.html
像Kirk建议的那样,能够提供类似于范围分布和创建时间的相似度排名的统计方法似乎是正确的方法。我需要使用SAS EG或任何免费工具来实现它。
- user1767316
2
一个技术方法可能在这里找到 http://www.vldb.org/pvldb/vldb2010/papers/R72.pdf,但实际操作仍然很不错;-) - user1767316
我仍然使用我的脚本。它通过测试
SELECT COUNT(DISTINCT colname) = SELECT COUNT (DISTINCT *) 来查找候选主键,并通过测试其值集合是否包含在候选主键的值集合中来查找候选外键,这也可以通过单个 SELECT 查询完成。这会找到很多错误的结果。 - reinierpost0
我不知道有哪些软件可以帮助你搜索所需内容,但以下查询将帮助您入门。它列出了当前数据库中的所有外键关系。
SELECT
K_Table = FK.TABLE_NAME,
FK_Column = CU.COLUMN_NAME,
PK_Table = PK.TABLE_NAME,
PK_Column = PT.COLUMN_NAME,
Constraint_Name = C.CONSTRAINT_NAME
FROM
INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS C
INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS FK
ON C.CONSTRAINT_NAME = FK.CONSTRAINT_NAME
INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS PK
ON C.UNIQUE_CONSTRAINT_NAME = PK.CONSTRAINT_NAME
INNER JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE CU
ON C.CONSTRAINT_NAME = CU.CONSTRAINT_NAME
INNER JOIN (
SELECT
i1.TABLE_NAME,
i2.COLUMN_NAME
FROM
INFORMATION_SCHEMA.TABLE_CONSTRAINTS i1
INNER JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE i2
ON i1.CONSTRAINT_NAME = i2.CONSTRAINT_NAME
WHERE
i1.CONSTRAINT_TYPE = 'PRIMARY KEY'
) PT
ON PT.TABLE_NAME = PK.TABLE_NAME
希望这可以帮到你。
- talha2k
3
谢谢,但我的问题是关于没有明确定义这样的约束条件的情况。 - reinierpost
1我认为你应该访问这个链接:
http://www.ironspeed.com/Designer/8.0.2/WebHelp/Part_II/Adding_Virtual_Foreign_Key_Relationships.htm希望对你有所帮助。 - talha2k
是的,那就是我正在寻找的功能!但是Ironspeed Designed似乎没有列出数据库中所有虚拟主键和外键。这就是我要求的部分。 - reinierpost
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接