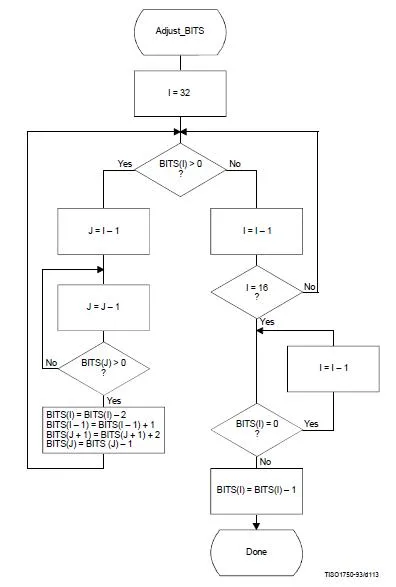
在JPEG标准中,Huffman表是通过两个步骤从一组统计数据中生成的。其中一个步骤是实现此图片中给出的函数/方法(该图片在JPEG标准的附件K中给出):
 问题在于,在标准(附件C)中先前已经指出:
问题在于,在标准(附件C)中先前已经指出:
“Huffman表是根据16字节列表(BITS)中指定的内容指定的,该列表给出了从1到16的每个编码长度的编码数。然后,是8位符号值(HUFFVAL)的列表,为每个符号分配了Huffman编码。”
显然,BITS是由16个元素组成的列表。但在上面的图片中,i首先设置为32(i = 32),然后我们想访问BITS[i]。也许我误解了某些东西,请有人给我答案。
这里是图片的JPEG标准描述: 图K.3 给出了调整BITS列表的过程,以确保没有代码超过16位。由于最长的Huffman代码是成对的,因此这些代码将成对地从此长度类别中移除。该对的前缀(比一个位短)被分配给其中一个;然后(跳过该前缀长度的BITS项)将下一个最短的非零BITS项中的代码字转换为两个代码字的前缀,长度加一。将BITS列表减少到最大码长度为16位后,最后一步会从代码长度计数中删除保留的代码点。
以下是图片的代码:
问题在于,在标准(附件C)中先前已经指出:“Huffman表是根据16字节列表(BITS)中指定的内容指定的,该列表给出了从1到16的每个编码长度的编码数。然后,是8位符号值(HUFFVAL)的列表,为每个符号分配了Huffman编码。”
显然,BITS是由16个元素组成的列表。但在上面的图片中,i首先设置为32(i = 32),然后我们想访问BITS[i]。也许我误解了某些东西,请有人给我答案。
这里是图片的JPEG标准描述: 图K.3 给出了调整BITS列表的过程,以确保没有代码超过16位。由于最长的Huffman代码是成对的,因此这些代码将成对地从此长度类别中移除。该对的前缀(比一个位短)被分配给其中一个;然后(跳过该前缀长度的BITS项)将下一个最短的非零BITS项中的代码字转换为两个代码字的前缀,长度加一。将BITS列表减少到最大码长度为16位后,最后一步会从代码长度计数中删除保留的代码点。
以下是图片的代码:
void adjustBitLengthTo16Bits(vector<char>&BITS){
int i=32,j=0;
while(1){
if(BITS[i]>0){
j=i-1;
j--;
while(BITS[j]<=0)
j--;
BITS[i]=BITS[i]-2;
BITS[i-1]=BITS[i-1]+1;
BITS[j+1]=BITS[j+1]+2;
BITS[j]=BITS[j]-1;
continue;
}
else{
i--;
if(i!=16)
continue;
while(BITS[i]==0)
i--;
BITS[i]--;
return;
}
}
}