我有一个项目,正在使用Haskell构建一个决策树(Decision Tree)。
生成的决策树将具有多个互不相关的分支,因此我认为它们可以并行构造。
DecisionTree数据类型定义如下:
data DecisionTree =
Question Filter DecisionTree DecisionTree |
Answer DecisionTreeResult
instance NFData DecisionTree where
rnf (Answer dtr) = rnf dtr
rnf (Question fil dt1 dt2) = rnf fil `seq` rnf dt1 `seq` rnf dt2
这里是构建树的算法部分。
constructTree :: TrainingParameters -> [Map String Value] -> Filter -> Either String DecisionTree
constructTree trainingParameters trainingData fil =
if informationGain trainingData (parseFilter fil) < entropyLimit trainingParameters
then constructAnswer (targetVariable trainingParameters) trainingData
else
Question fil <$> affirmativeTree <*> negativeTree `using` evalTraversable parEvalTree
where affirmativeTree = trainModel trainingParameters passedTData
negativeTree = trainModel trainingParameters failedTData
passedTData = filter (parseFilter fil) trainingData
failedTData = filter (not . parseFilter fil) trainingData
parEvalTree :: Strategy DecisionTree
parEvalTree (Question f dt1 dt2) = do
dt1' <- rparWith rdeepseq dt1
dt2' <- rparWith rdeepseq dt2
return $ Question f dt1' dt2'
parEvalTree ans = return ans
trainModel 递归调用 constructTree。与并行相关的代码行为:
Question fil <$> affirmativeTree <*> negativeTree `using` evalTraversable parEvalTree
我正在使用 GHC 标志
-threaded -O2 -rtsopts -eventlog 构建这个项目,并且使用以下命令运行它:
stack exec -- performance-test +RTS -A200M -N -s -l
(我在一台拥有两个核心的机器上)。但是看起来它并没有并行运行任何东西。
SPARKS: 164 (60 converted, 0 overflowed, 0 dud, 0 GC'd, 104 fizzled)
INIT time 0.000s ( 0.009s elapsed)
MUT time 29.041s ( 29.249s elapsed)
GC time 0.048s ( 0.015s elapsed)
EXIT time 0.001s ( 0.006s elapsed)
Total time 29.091s ( 29.279s elapsed)
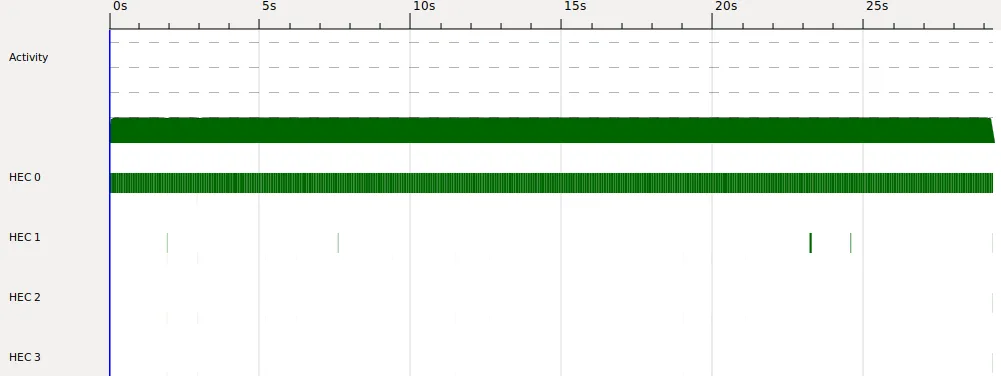
我怀疑使用 rdeepseq 和并行策略时可能存在递归调用问题。如果有经验的 Haskeller 参与讨论,那真是太好了 :)