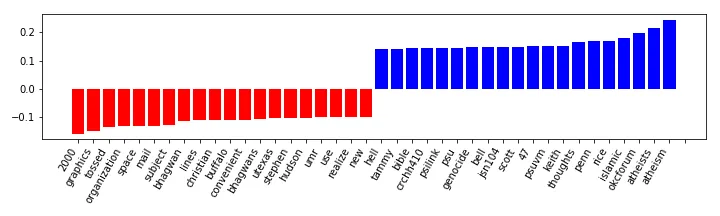
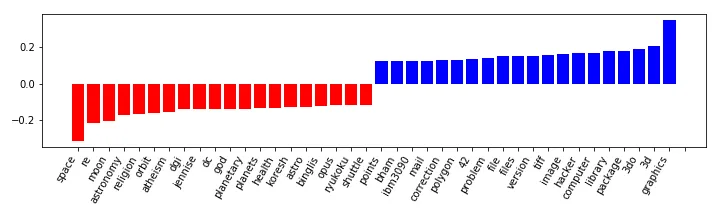
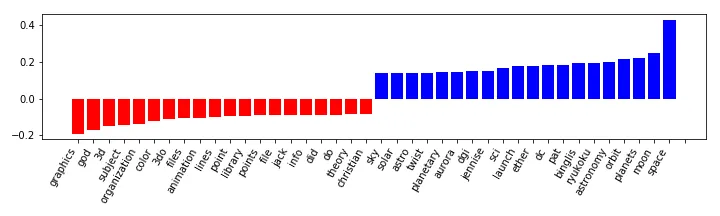
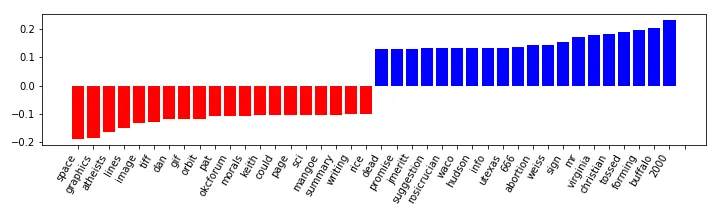
我使用这个函数绘制每个标签的最佳和最差特征(coef)。
"top"列表中第一个条目的索引为39336。这与词汇表中的条目39337-26728=12608相对应。我需要更改代码中的什么内容才能使其适用?
def plot_coefficients(classifier, feature_names, top_features=20):
coef = classifier.coef_.ravel()
for i in np.split(coef,6):
top_positive_coefficients = np.argsort(i)[-top_features:]
top_negative_coefficients = np.argsort(i)[:top_features]
top_coefficients = np.hstack([top_negative_coefficients, top_positive_coefficients])
# create plot
plt.figure(figsize=(15, 5))
colors = ["red" if c < 0 else "blue" for c in i[top_coefficients]]
plt.bar(np.arange(2 * top_features), i[top_coefficients], color=colors)
feature_names = np.array(feature_names)
plt.xticks(np.arange(1, 1 + 2 * top_features), feature_names[top_coefficients], rotation=60, ha="right")
plt.show()
将其应用于sklearn.LinearSVC:
if (name == "LinearSVC"):
print(clf.coef_)
print(clf.intercept_)
plot_coefficients(clf, cv.get_feature_names())
使用的CountVectorizer的维度为(15258, 26728)。
这是一个具有6个标签的多类决策问题。使用.ravel返回长度为6*26728=160368的平坦数组。这意味着所有高于26728的索引都超出了轴1的范围。以下是一个标签的顶部和底部索引:
i[ 0. 0. 0.07465654 ... -0.02112607 0. -0.13656274]
Top [39336 35593 29445 29715 36418 28631 28332 40843 34760 35887 48455 27753
33291 54136 36067 33961 34644 38816 36407 35781]
i[ 0. 0. 0.07465654 ... -0.02112607 0. -0.13656274]
Bot [39397 40215 34521 39392 34586 32206 36526 42766 48373 31783 35404 30296
33165 29964 50325 53620 34805 32596 34807 40895]
"top"列表中第一个条目的索引为39336。这与词汇表中的条目39337-26728=12608相对应。我需要更改代码中的什么内容才能使其适用?
X_train = sparse.hstack([training_sentences,entities1train,predictionstraining_entity1,entities2train,predictionstraining_entity2,graphpath_training,graphpathlength_training])
y_train = DFTrain["R"]
X_test = sparse.hstack([testing_sentences,entities1test,predictionstest_entity1,entities2test,predictionstest_entity2,graphpath_testing,graphpathlength_testing])
y_test = DFTest["R"]
尺寸:
(15258, 26728)
(15258, 26728)
(0, 0) 1
...
(15257, 0) 1
(15258, 26728)
(0, 0) 1
...
(15257, 0) 1
(15258, 26728)
(15258L, 1L)
File "TwoFeat.py", line 708, in plot_coefficients
colors = ["red" if c < 0 else "blue" for c in i[top_coefficients]]
MemoryError