有人可以解释一下这两种实现方式的主要区别(优缺点)吗?
对于一个库(library),推荐使用哪种实现方式?
有人可以解释一下这两种实现方式的主要区别(优缺点)吗?
对于一个库(library),推荐使用哪种实现方式?
维基百科关于哈希表的文章 比我能够随口介绍的不同哈希表方案有更好的解释和概述。事实上,你最好阅读那篇文章而不是在这里问问题。 :)
话虽如此...
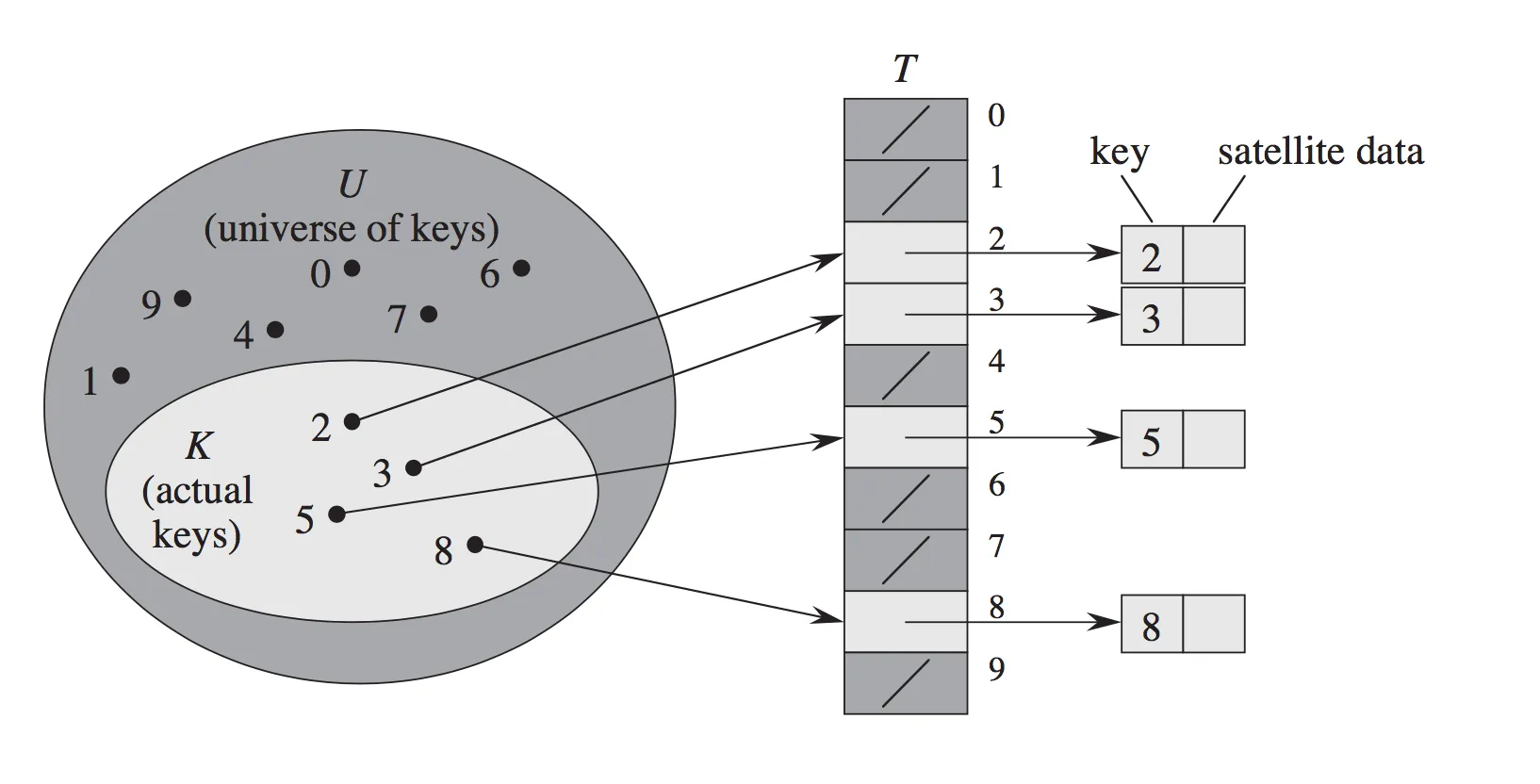
链式哈希表将索引建立在指向链接列表头部的指针数组中。每个链接列表单元格都有分配给它的键和插入该键的值。当您想要使用其键查找特定元素时,将使用该键的哈希来计算应遵循哪个链接列表,然后遍历该特定列表以找到您需要的元素。如果哈希表中有多个键具有相同的哈希,则您将具有多个元素的链接列表。
链式哈希的缺点是必须遵循指针以搜索链接列表。优点是,即使负载因子(哈希表中元素数量与存储桶数组长度之比)超过了1,链式哈希表也只会线性变慢。
开放寻址哈希表将索引建立在指向(键,值)对的指针数组中。使用键的哈希值来确定首先查看数组中的哪个位置。如果哈希表中有多个键具有相同的哈希,则使用一些方案来决定要查看哪个其他位置。例如,线性探测是在选择的下一个位置上查看,然后在该位置的下一个位置上查看,以此类推,直到找到与您正在寻找的键匹配的位置或者找到一个空位置(这种情况下不存在该键)。
当负载因子较低时,开放寻址比链式哈希更快,因为不需要在列表节点之间跟随指针。如果负载因子接近1,它会变得非常非常慢,因为您通常必须搜索存储桶数组中许多插槽,才能找到要么是您要查找的键,要么是空插槽。此外,哈希表中的元素数量不能超过桶数组中的条目数量。
为了应对当哈希表的负载因子接近1时,所有哈希表都会变慢(在某些情况下甚至会完全瘫痪)的事实,实用的哈希表实现会在负载因子超过某个值时(通常约为0.7),使桶数组变得更大(通过分配新的桶数组,并将元素从旧数组复制到新数组中,然后释放旧数组)。
上述内容有许多变化。请参阅维基百科文章,它非常好。
对于一个预期被其他人使用的库,我强烈建议进行试验。由于它们通常具有很高的性能关键性,使用已经经过精心调整的哈希表实现通常是最佳选择。有许多开源的BSD、LGPL和GPL许可的哈希表实现。
例如,如果你正在使用GTK,则会发现GLib中有一个好的哈希表。
我的理解(简单来说)是,这两种方法都有优缺点,尽管大多数库使用链接策略。
链接策略:
在这里,哈希表数组映射到项目的链接列表。如果冲突数量相当小,则效率很高。最坏情况是O(n),其中n是表中元素的数量。
线性探测开放寻址法:
在这里,当发生冲突时,转移到下一个索引,直到找到空闲位置为止。因此,如果冲突数量较少,这非常快捷和空间有效。这里的限制是表中条目的总数受到数组大小的限制。这在链接中不是这种情况。
还有另一种方法,即基于二叉搜索树的链接。在这种方法中,当冲突发生时,它们会存储在二叉搜索树中而不是链接列表中。因此,最坏情况下,这里的复杂度将是O(log n)。实际上,在存在极不均匀分布的情况下,这种方法最适合。
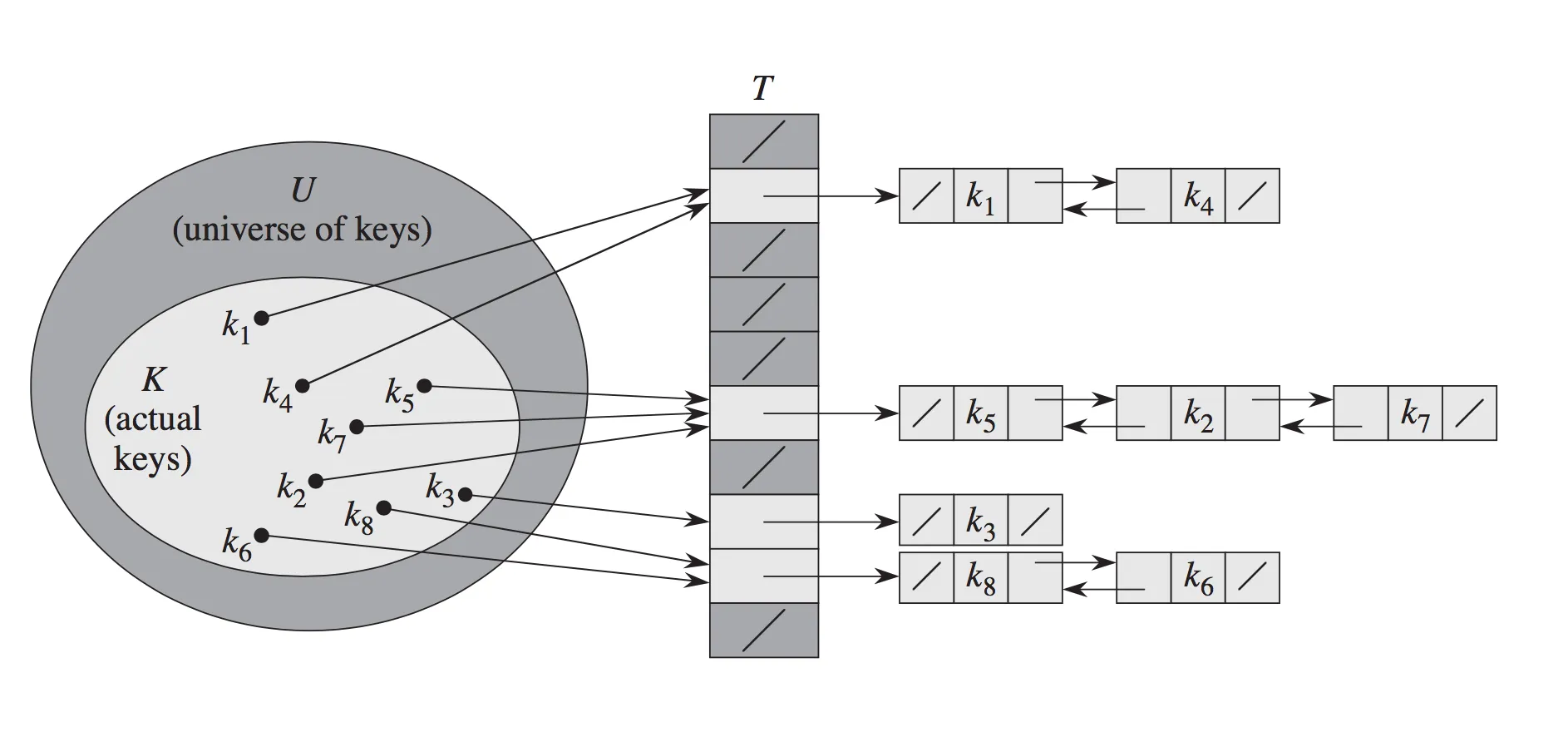
 链接法:
链接法:
开放地址法 vs. 链式地址法
如果将键作为哈希表本身的条目保留,则线性探测、双重散列和随机散列是合适的...这被称为“开放地址法”,也称为“闭散列”。
另一个想法:哈希表中的条目只是指向链表头部的指针(“链”);链表的元素包含键...这被称为“链式地址法”,也称为“开放散列”。
使用链式地址法可以轻松解决冲突:如果键不存在于其链表中,则将其插入链表中。(可以使用比链表更高级的数据结构,但链表在平均情况下非常有效,我们将看到)让我们来分析这些策略的时间成本。
来源: http://cseweb.ucsd.edu/~kube/cls/100/Lectures/lec16/lec16-25.html
如果在创建哈希表时不知道要插入的项数,链式哈希表比开放地址法更可取。
增加负载因子(项数/表大小)会导致开放地址法哈希表的性能严重下降,但在链式哈希表中性能仅线性下降。
如果您处理的是低内存并想要减少内存使用量,请选择开放地址法。如果您不担心内存并想要速度,请选择链式哈希表。
当有疑问时,请使用链式哈希表。添加比预期更多的数据不会导致性能急剧下降。