我有来自IBM的一些幻灯片,名为:"从Java代码到Java堆:理解应用程序的内存使用情况",它说,当我们使用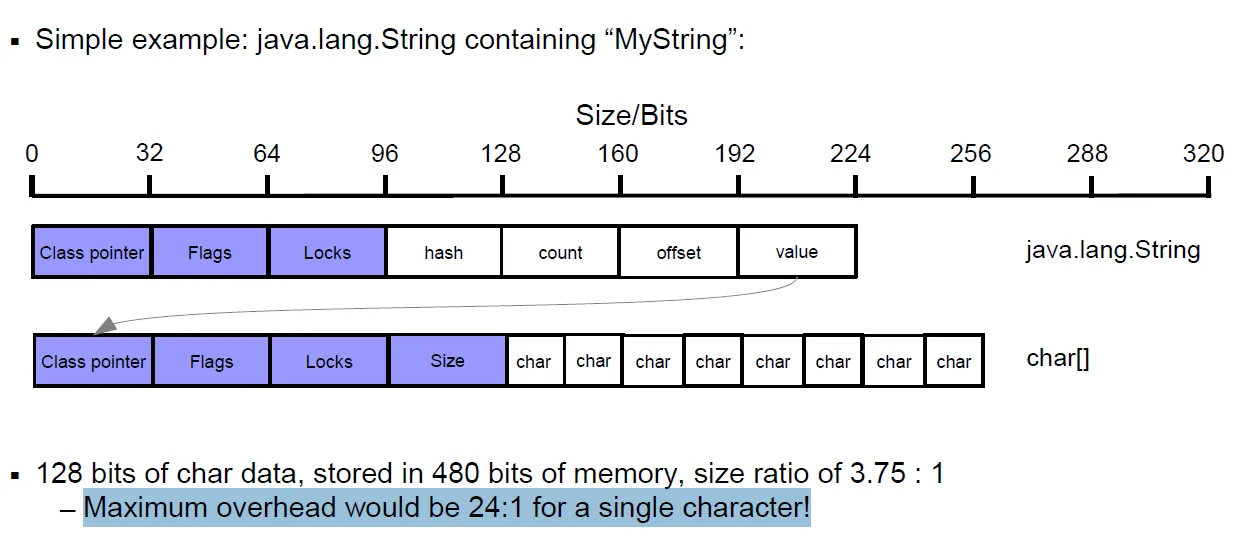
String而不是char[]时,存在最大开销24:1,但我不能理解这里所指的开销是什么。 有人可以帮忙吗?
来源:
String而不是char[]时,存在最大开销24:1,但我不能理解这里所指的开销是什么。 有人可以帮忙吗?
来源:
这个图表涉及到JDK 6- 32位。
在Java 7之前的世界中,字符串被实现为指向char[]数组区域的指针:
// "8 (4)" reads "8 bytes for x64, 4 bytes for x32"
class String{ //8 (4) house keeping + 8 (4) class pointer
char[] buf; //12 (8) bytes + 2 bytes per char -> 24 (16) aligned
int offset; //4 bytes -> three int
int length; //4 bytes -> fields align to
int hash; //4 bytes -> 16 (12) bytes
}
所以我数了一下:
36 bytes per new String("a") for JDK 6 x32 <-- the overhead from the article
56 bytes per new String("a") for JDK 6 x64.
仅作比较,在JDK 7+中,String是一个仅包含char[]缓冲区和一个hash字段的类。
class String{ //8 (4) + 8 (4) bytes -> 16 (8) aligned
char[] buf; //12 (8) bytes + 2 bytes per char -> 24 (16) aligned
int hash; //4 bytes -> 8 (4) aligned
}
所以它是:
28 bytes per String for JDK 7 x32
48 bytes per String for JDK 7 x64.
更新
对于比率为3.75:1的情况,请参见下面@Andrey的解释。随着字符串长度的增加,这个比例会降至1。
有用的链接:
480/128 = 3.75 是 MyString 的比率,而对于单个字符的字符串则为 368/16 = 23。两个字段被删除后,数字只是稍微好一些。 - Marko Topolnikchar[] 不存储零终止符。Python则完全不同,它更加面向C语言。 - Marko Topolnikchar[],我们有:2 *(4-(length + 2)%4))java.lang.String,我们有:"MyString"作为String对象存储所需的内存量:12 + 16 + (12 + 4 + 2 * "MyString".length + 2 * ("MyString".length % 2)) = 60 bytes.
从另一方面来看,我们知道仅存储数据(不包括数据类型、长度或其他任何信息)需要:
2 * "MyString".length = 16 bytes
开销是60 / 16 = 3.75
同样地,对于单个字符数组,我们得到“最大开销”:
12 + 16 + (12 + 4 + 2 * "a".length + 2 * ("a".length % 2)) = 48 bytes
2 * "a".length = 2 bytes
48 / 2 = 24
我曾从stackoverflow的旧答案中了解到,无法获得它。在Oracle的JDK中,字符串具有四个实例级字段:
A character array
An integral offset
An integral character count
An integral hash value