我试图训练一个执行图像分割的CNN模型,但如果我有多个图像样本,如何创建ground truth令我感到困惑?
图像分割可以将输入图像中的每个像素分类到预定义的类别中,例如汽车、建筑、人或其他任何类别。
有没有工具或一些好的想法来为图像分割创建ground truth呢?
谢谢!
图像分割可以将输入图像中的每个像素分类到预定义的类别中,例如汽车、建筑、人或其他任何类别。
有没有工具或一些好的想法来为图像分割创建ground truth呢?
谢谢!
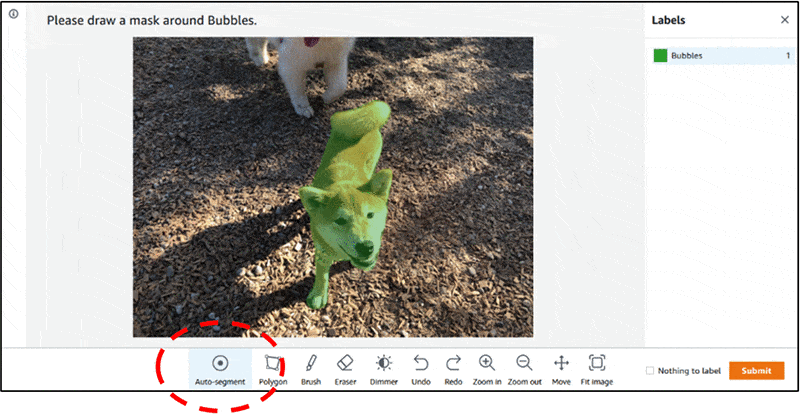
对于语义分割,图像的每个像素都应该被标记。有以下三种方法来解决这个任务:
基于矢量 - 多边形、折线
基于像素 - 画笔、橡皮擦
人工智能工具
在Supervisely中,可以使用工具执行1、2、3。
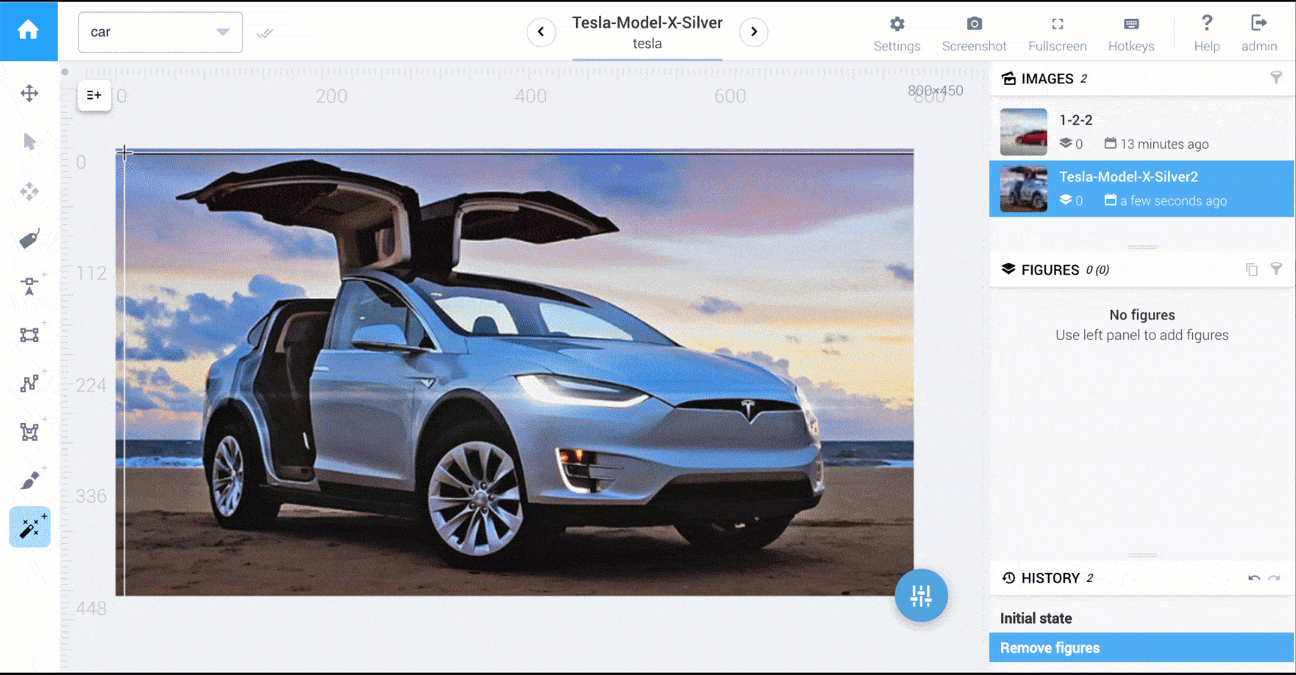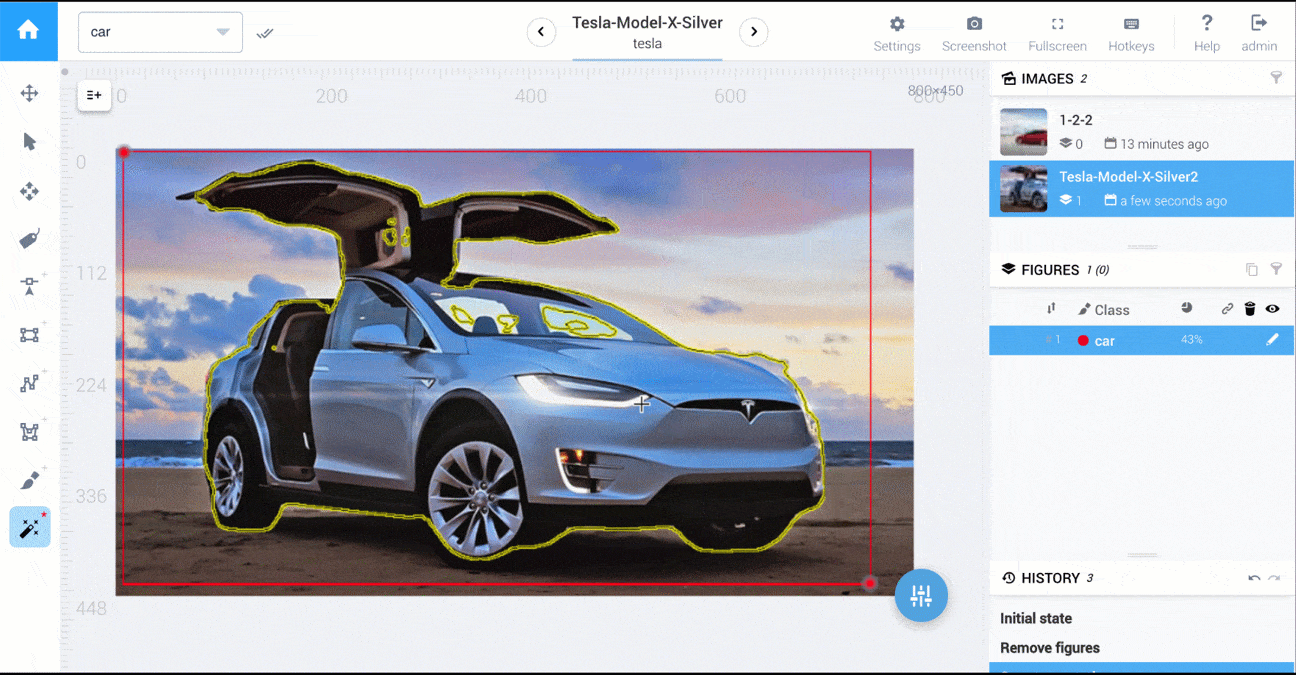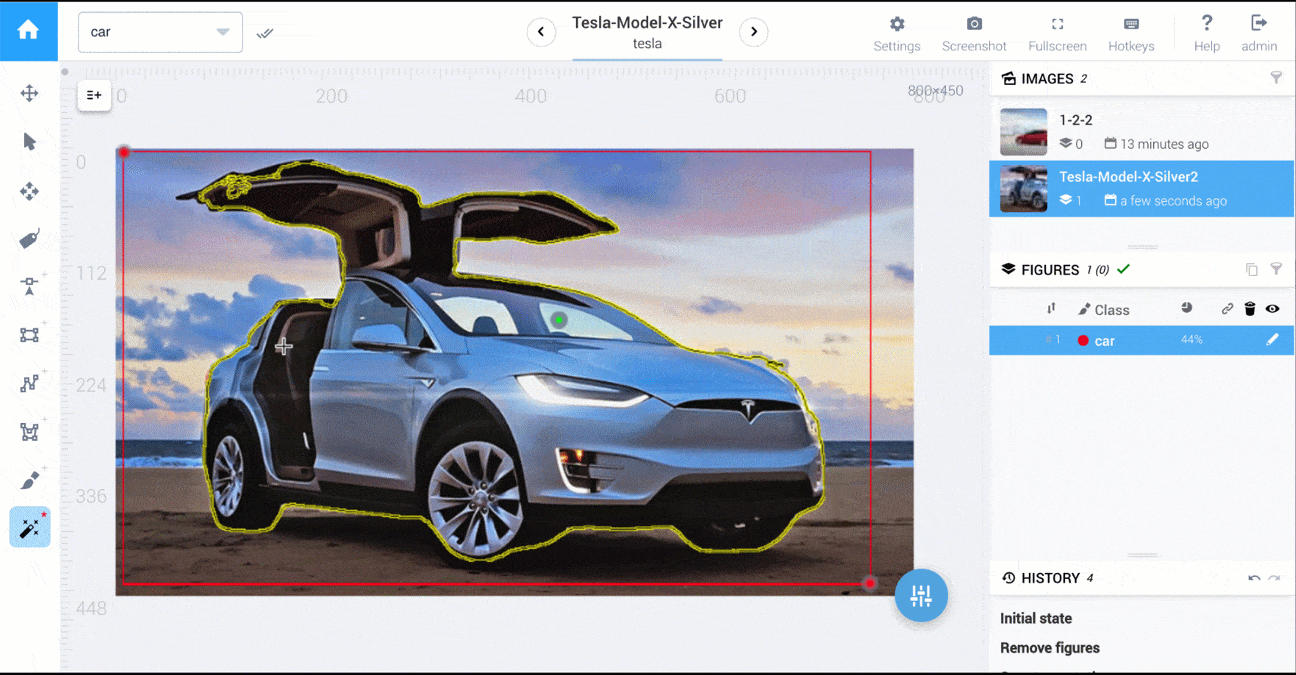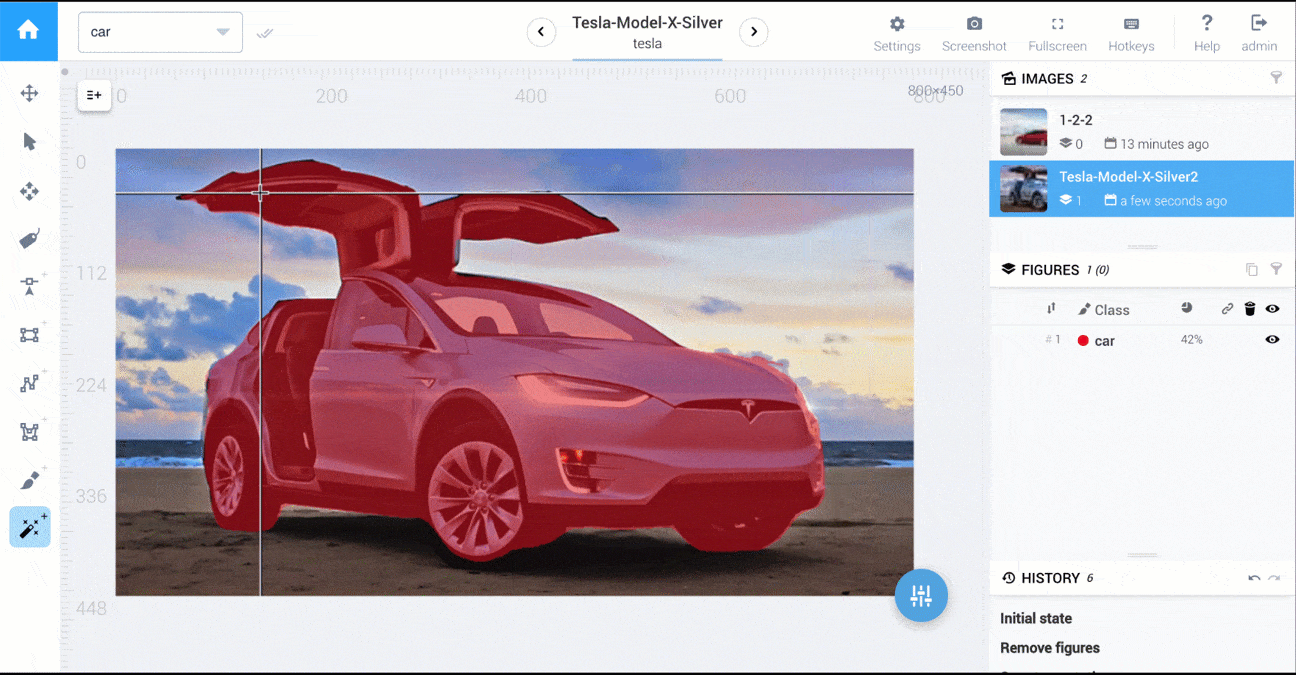
有一个工具让我想到了,那就是MIT的LabelMe工具箱:这个工具箱主要用于浏览数据集中现有的标记图像,但它也有一个选项可以注释新图像。
我创建了一个名为COCO Annotator的开源工具:它提供了其他工具无法实现的功能:
ITK-SNAP是专为医学图像分割而设计的。它易于学习,但功能强大。你可以试试。
整个过程如下:
注释过程详细信息
一般来说,矢量基础工具更加准确。例如,左侧是4个多边形点,右侧是一个画笔。

令人反感的是,追踪点甚至可以更快。例如,在这里,我只需将鼠标移动到轮廓上,就会记录下来:

但实际上它被存储为点:

使用其他形状
例如,您可以使用椭圆或圆形来创建分割掩模。实际上没有手动创建多边形的要求。


自动边框
想要实现像素覆盖率达到100%的主要概念之一是自动边框。基本上,它只是意味着对象的边缘相交得很好。例如,在Diffgram中,您可以选择两个点,它将创建一个匹配的边框。
这里有一个例子:

最后还有许多其他概念,如预标记、复制到下一个、跟踪等。
工具
Diffgram的分割标注软件是图像和视频注释的绝佳工具选择。它采用开放式内核,您可以在您的Kubernetes集群上运行它。
您可以在整个数据集上使用平均化和归一化技术,以创建您的基准,并标记不同的结构。为此,您可以考虑创建所谓的“模板”。请确保最初所有数据都是共同注册的。
