作为问题比较广泛,我会尽力提供不同的见解并涉及到与
@Daniel's深入回答所展示内容有所不同的主题。
训练
数据并行化 vs 模型并行化
如@Daniel所提到的,数据并行化更常用且更容易正确实现。模型并行化的主要缺点是需要等待神经网络的一部分以及它们之间的同步。
假设你有一个简单的前馈神经网络,由5个不同的GPU扩展,每个设备对应一个层。在这种情况下,在每次前向传递期间,每个设备都必须等待来自前一层的计算。在这种简单情况下,设备之间的数据复制和同步需要更长时间,并且不会带来好处。
另一方面,有些模型更适合于模型并行化,例如Inception networks,如下图所示:
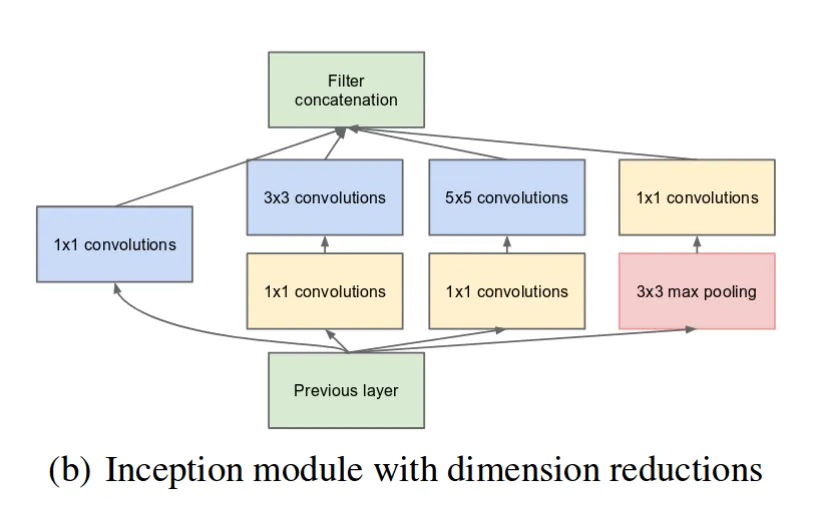
这里您可以看到来自前一层的
4个独立路径,可以并行执行,只有
2个同步点(
Filter concatenation和
Previous Layer)。
问题
例如,通过图本身的反向传播可以进行并行化,例如将不同的层托管在不同的机器上,因为(我认为?)autodiff图始终是DAG。
这并不容易。梯度是基于损失值(通常)计算的,您需要知道更深层次的梯度才能计算更浅层次的梯度。就像上面所说,如果您有独立路径,则更容易并且可能有所帮助,但在单个设备上更容易。
我相信这也被称为梯度积累(?)
不,实际上是在多个设备上进行缩减。您可以在
PyTorch教程中看到一些内容。梯度累积是指您运行前向传递(在单个或多个设备上)
N次并反向传播(梯度保留在图中,并且值在每个传递期间添加),优化器仅采取一步来更改神经网络的权重(并清除梯度)。在这种情况下,损失通常被分成没有优化器的步骤数。这用于更可靠的梯度估计,通常在无法使用大批量时使用。
跨设备的缩减如下所示:
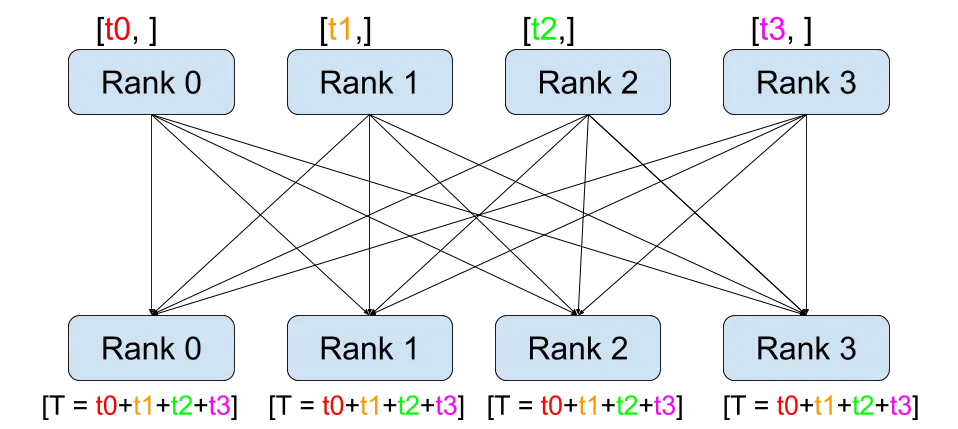
这是数据并行中的全局归约,每个设备计算值并将其发送到所有其他设备,并在那里进行反向传播。
每种策略对于什么类型的问题或神经网络更好的时间是什么时候?
如上所述,如果您有足够的数据且样本很大(最多可以一次处理8k个样本或更多而不会遇到非常大的困难),则数据并行几乎总是可以的。
现代库支持哪些模式?
tensorflow和pytorch都支持两种方式,大多数现代和维护良好的库都以某种方式实现了这些功能。
是否可以同时组合所有四种(2x2)策略?
是的,您可以在机器内外并行化模型和数据。
同步与异步
异步
由
@Daniel简要描述,但值得一提的是更新不是完全分开的。这没有多大意义,因为我们本质上会基于它们的批次训练N个不同的模型。
相反,存在一个全局参数空间,每个副本都应异步共享计算更新(因此前向传递、反向传递、使用优化器计算更新并将此更新共享到全局参数)。
然而,这种方法有一个问题:没有保证一个工作进程计算前向传递时另一个工作进程已经更新了参数,因此更新是根据旧参数集计算的,这被称为“过时梯度”。由于这个原因,收敛可能会受到影响。
另一种方法是为每个工作进程计算N个步骤和更新,然后进行同步,但这种方法并不经常使用。
这部分内容基于优秀的
blogpost,如果感兴趣,你应该一定要阅读它(其中还有更多关于过时性和一些解决方案的内容)。
同步
大多数情况下,如上所述,有不同的方法,但PyTorch从网络中收集输出并在其上进行反向传播(torch.nn.parallel.DistributedDataParallel)。顺便说一下,你应该仅使用这个(不要使用torch.nn.DataParallel),因为它可以克服Python的GIL问题。
总结
- 当需要加速时,数据并行化几乎总是被使用的,因为您只需要在每个设备上复制神经网络(可以通过网络或单台机器内部),在前向传递期间在每个设备上运行一部分批次,将它们连接成一个单一的批次(同步)在一个设备上进行反向传播。
- 有多种方法可以进行数据并行化,已由@Daniel介绍过。
- 当模型太大无法放在单台计算机上(OpenAI's GPT-3是一个极端情况),或者当体系结构适用于此任务时,才会进行模型并行化,但这两种情况很少发生,据我所知。
- 模型具有更多和更长的并行路径(同步点),则可能更适合进行模型并行化。
- 重要的是要在相似的时间以及相似的负载下启动工作人员,以便在同步方法中不需要等待同步进程,或在异步方法中不会获得陈旧的梯度(尽管在后一种情况下这还不足够)。
服务
小型模型
由于您需要大型模型,我不会深入探讨小型模型的选项,只简单提及一下。
如果您想通过网络为多个用户提供服务,您需要某种方式来扩展您的架构(通常是像GCP或AWS这样的云)。您可以使用
Kubernetes和它的POD,或预先分配一些服务器来处理请求,但这种方法效率低下(少量用户和运行服务器将产生无意义的成本,而大量用户可能会使基础设施停滞并花费太长时间来处理请求)。
另一种方法是使用基于无服务器的自动缩放。资源将根据每个请求提供,因此具有很大的扩展能力+在流量较低时不支付费用。您可以查看
Azure Functions,因为它们正在改进ML / DL任务,或
torchlambda用于PyTorch(免责声明,我是作者)用于较小的模型。
大型模型
如前所述,您可以使用Kubernetes与自定义代码或可用工具。
在第一种情况下,您可以像训练模型一样传播模型,但仅执行前向传递。通过这种方式,即使是巨大的模型也可以放在网络上(再次提到
GPT-3具有175B参数),但需要大量工作。
在第二种情况下,
@Daniel 提供了两种可能性。其他值得一提的可能包括(阅读相应文档,因为它们具有许多功能):
对于PyTorch,您可以在这里阅读更多信息,而Tensorflow则有很多服务功能可供使用,通过Tensorflow Extended (TFX)即可轻松实现。
来自评论区的问题
在单台机器内和跨多台机器之间,是否存在某些形式的并行性更好?
最佳的并行形式可能是在一个巨型计算机内,以最小化设备之间的传输。此外,在PyTorch中有不同的后端可以选择(mpi,gloo,nccl),并非所有后端都支持直接在设备之间发送、接收、减少等数据(有些可能支持CPU之间,其他GPU之间)。如果设备之间没有直接链接,则必须首先将其复制到另一个设备,然后再复制到目标设备(例如,在其他机器上的GPU->主机上的CPU->主机上的GPU)。请参阅
pytorch info。数据越多、网络越大,计算并行化就越有利可图。如果整个数据集可以适应单个设备,则不需要并行处理。此外,还应考虑诸如互联网传输速度、网络可靠性等因素。这些成本可能超过了收益。
如果你有大量数据(比如ImageNet的1000000张图片)或者大样本(比如2000x2000像素的图片),那么尽可能在单台机器上进行数据并行化以最小化机器之间的传输。只有在没有其他选择的情况下(例如无法放入GPU中),才分布式模型。当整个数据集可以轻松放入内存且从中读取速度最快时(例如MNIST数据集),并行化训练几乎没有意义。
为什么要构建专门用于机器学习的硬件,例如TPUs?
CPU不适合高度并行计算(例如矩阵乘法),而且CPU可能会被许多其他任务占用(例如数据加载),因此使用GPU是有意义的。
由于GPU是为图形处理而创建的(因此代数变换),它可以承担一些CPU工作,并且可以专门化(与CPU相比,它具有更多的核心但更简单,例如V100)。
现在,TPU专门针对张量计算而设计(主要是深度学习),起源于Google,与GPU相比仍处于WIP状态。这些器件适用于某些类型的模型(主要是卷积神经网络),在这种情况下可以带来加速。此外,应该使用最大批次的设备(请参见
here),最好能够被
128整除。您可以将其与NVidia的Tensor Cores技术(GPU)进行比较,在这种技术中,您只需使用可被
16或
8(分别为
float16精度和
int8)整除的批次(或层大小)即可实现良好的利用率。(尽管更多的批次越好,并且取决于核心数、确切的显卡和许多其他因素,可以参考
here一些指南)。
另一方面,尽管两个主要框架(
tensorflow正式支持,而PyTorch通过
torch_xla包支持),但TPU的支持仍然不是最好的选择。总的来说,在深度学习中,GPU现在是一个很好的默认选择,对于卷积重型结构,TPUs可能会带来一些问题。此外(再次感谢@Daniel),TPUs更加节能,因此在比较单个浮点操作成本时应该更便宜。
Horovod,这是在使用TS/Keras进行分布式计算时推荐的方法。以下是链接 https://horovod.readthedocs.io/en/stable/summary_include.html - Matus Dubrava