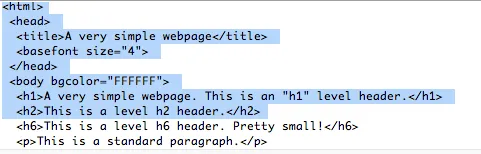
我正在做一个学校项目,尝试解析HTML网页以仅显示标签,就像下面的输出一样,不带闭合标签。(我手动编写)
<html>
<head>
<title>
<basefont>
<body>
<h1>
<h2>
这是我目前仅在主方法中的代码。
public class ReadWithScanner {
public static void main(String[] args) throws IOException
{
String URL ="http://csb.stanford.edu/class/public/pages/sykes_webdesign/05_simple.html";
Document doc = Jsoup.connect(URL).get();
//Element p = doc.select("p");
//Elements p = doc.getElementsByTag("h6");
Elements p = doc.select("html");
//System.out.println(p);
DoublyLinkedList theList = new DoublyLinkedList();
theList.insert(p); // insert at front
theList.displayTree();
}
这是我的输出结果的几行代码。