何时应使用Kruskal算法而不是Prim算法(反之亦然)?
如果你有一个边数众多的图,可以使用Prim算法。
对于一个有V个顶点和E条边的图,Kruskal算法的运行时间为O(E log V),而如果使用斐波那契堆(Fibonacci Heap), Prim算法可以在O(E + V log V)的摊销时间内运行。
当图是密集图,边数远大于顶点数时,Prim算法在极限情况下明显更快。在典型情况(稀疏图)下,Kruskal算法表现更好,因为它使用更简单的数据结构。
11
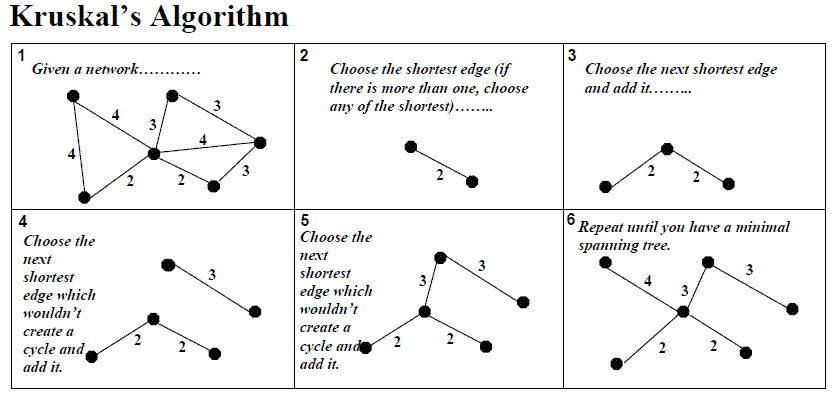
Kruskal算法将通过添加下一个最便宜的边来从最便宜的边增加解决方案,前提是它不会创建循环。
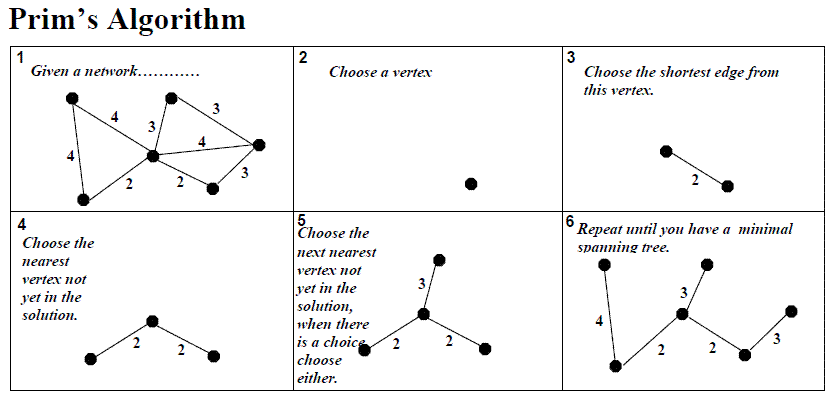
Prim算法将从随机顶点开始增加解决方案,即不在解决方案中但通过最便宜的边与其相连的下一个最便宜的顶点。
这里附有关于该主题的有趣表格。
 如果您使用最佳形式的Kruskal和Prim进行实现:分别采用联合查找和斐波那契堆,则会注意到Kruskal相比Prim更容易实现。
如果您使用最佳形式的Kruskal和Prim进行实现:分别采用联合查找和斐波那契堆,则会注意到Kruskal相比Prim更容易实现。使用斐波那契堆的Prim更难,主要是因为您必须维护一个记录图节点和堆节点之间双向链接的簿记表。使用Union Find则相反,结构很简单,甚至可以直接以几乎没有额外成本产生mst。
4
V-1 条边时,你就知道你已经找到了一棵树。 - mikedu95我知道您没有要求这个,但是如果您有更多的处理单元,您应该始终考虑使用波罗夫卡算法,因为它可能很容易地并行化-因此它具有比Kruskal和Jarník-Prim算法更高的性能优势。
Kruskal 的最坏时间复杂度是 O(E log E),因为我们需要对边进行排序。 Prim 的最坏时间复杂度是 O(E log V),使用 优先队列 可以得到更好的结果,甚至可以达到 O(E+V log V) 使用 Fibonacci Heap. 当图中的边很少时,比如 E=O(V),或者已经排好序或者可以在线性时间内排序时,应该使用 Kruskal 算法。 当图中的边很多时,比如 E=O(V²) 时,应该使用 Prim 算法。
1
Kruskal算法的性能会更好,如果边可以在线性时间内进行排序,或者已经有序。
如果边数与顶点数之比较高,则Prim算法更优。
Kruskal算法的一个重要应用是在单链聚类中。
考虑有n个顶点和一个完全图。为了获得k个这些n个点的聚类,运行Kruskal算法在排序后的边集的前n-(k-1)条边上。你将获得具有最大间距的图的k个聚类。
Kruskal算法的最佳时间复杂度为O(E logV)。使用fib堆优化后的Prim算法可以达到O(E+V lgV)。因此在稠密图上,Prim算法更好。
1
例如:
graph like this
_____________
| | |
| | |
|__________| |
给任何一个顶点命名为a、b、c、d、e、f。
在更密集的图中,Prim算法表现更好,而且我们在添加边时不需要过多关注环路问题,因为我们主要处理的是节点。在复杂的图形情况下,Prim算法比Kruskal算法更快。
原文链接