什么是低延迟数据访问?
我其实对 “LATENCY” 这个术语的定义感到困惑。
请问有人能详细解释一下 “延迟” 这个术语吗?
什么是低延迟数据访问?
我其实对 “LATENCY” 这个术语的定义感到困惑。
请问有人能详细解释一下 “延迟” 这个术语吗?
一个经典的例子:
备份磁带装满的马车是高延迟、高带宽的。这些备份磁带中包含了大量信息,但需要很长时间才能到达目的地。
低延迟网络对于流媒体服务非常重要。语音流媒体需要非常低的带宽(记得好像是4 kbps 的电话质量),但需要数据包快速到达。在高延迟网络上进行语音通话会导致讲话方之间存在时间延迟,即使有足够的带宽。
其他重要的延迟应用场景:
LATENCY - 响应时间的量 [us]BANDWIDTH - 单位时间内的数据流量 [GB/s]`LATENCY 数字非常神秘术语"延迟(latency)"可能会混淆,如果不小心考虑整个交易生命周期的上下文:参与线段 { 放大 | 重新计时 | 切换 | 多路复用/映射 | 路由 | EnDec 处理 (不提及密码学) | 统计-(解)压缩 },数据流持续时间和 framing / 线编码保护附加项 / ( opt. procotol, 如果存在,则是封装和重帧 ) 的额外过度开销,这些持续增加延迟(latency)但同时增加数据-VOLUME。
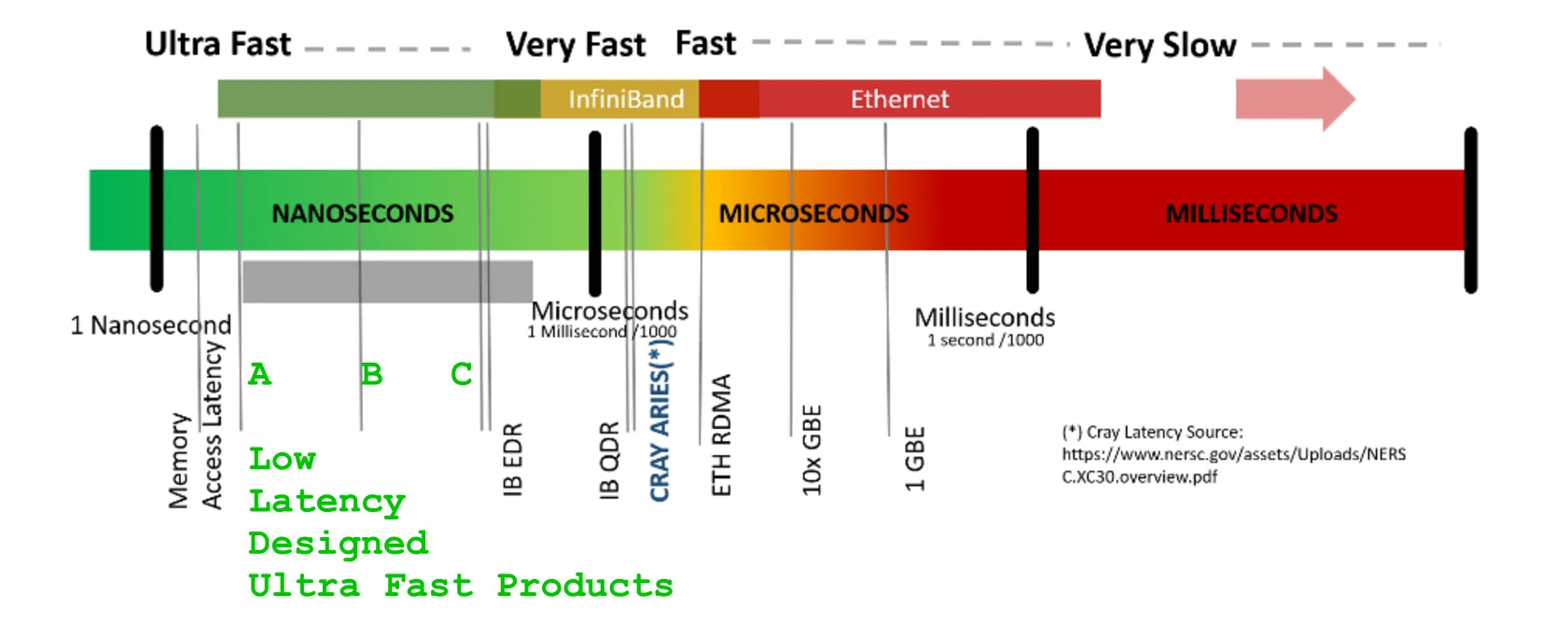 以 GPU 引擎的任何营销为例。展示的关于 GigaBytes 的
以 GPU 引擎的任何营销为例。展示的关于 GigaBytes 的DDR5和GHz的巨大数字暗示着它们是粗体的,但省略了告诉您的事实是,尽管有数不清的东西,但每个 SIMT 的多个核心,是所有的核心,都必须承受残酷的延迟(latency)-惩罚,并且要等待超过+400-800[GPU-clk]s才能从 GPU 过度炒作的 GigaHertz-Fast-DDRx-ECC-protected 内存银行接收第一个字节。
是的,您的超级引擎的GFLOPs/TFLOPs也需要等待! ... 因为(隐藏的)延迟(latency)
而你则伴随着所有完整的并行-马戏团...就因为延迟(latency)
(...任何营销花招都不能帮助,相信或不相信(忘记缓存承诺吧,这些不知道,在遥远/迟/遥远的内存单元中会有什么东西,所以无法向您提供这种延迟-"遥远"的谜题的单个位拷贝,从它们的浅表本地口袋))
延迟(latency)(和税收)不可避免只有高度专业的HPC设计才能帮助减少惩罚,但仍无法避免像税收一样的延迟LATENCY惩罚,除非进行一些巧妙的重新排列。
CUDA Device:0_ has <_compute capability_> == 2.0.
CUDA Device:0_ has [ Tesla M2050] .name
CUDA Device:0_ has [ 14] .multiProcessorCount [ Number of multiprocessors on device ]
CUDA Device:0_ has [ 2817982464] .totalGlobalMem [ __global__ memory available on device in Bytes [B] ]
CUDA Device:0_ has [ 65536] .totalConstMem [ __constant__ memory available on device in Bytes [B] ]
CUDA Device:0_ has [ 1147000] .clockRate [ GPU_CLK frequency in kilohertz [kHz] ]
CUDA Device:0_ has [ 32] .warpSize [ GPU WARP size in threads ]
CUDA Device:0_ has [ 1546000] .memoryClockRate [ GPU_DDR Peak memory clock frequency in kilohertz [kHz] ]
CUDA Device:0_ has [ 384] .memoryBusWidth [ GPU_DDR Global memory bus width in bits [b] ]
CUDA Device:0_ has [ 1024] .maxThreadsPerBlock [ MAX Threads per Block ]
CUDA Device:0_ has [ 32768] .regsPerBlock [ MAX number of 32-bit Registers available per Block ]
CUDA Device:0_ has [ 1536] .maxThreadsPerMultiProcessor [ MAX resident Threads per multiprocessor ]
CUDA Device:0_ has [ 786432] .l2CacheSize
CUDA Device:0_ has [ 49152] .sharedMemPerBlock [ __shared__ memory available per Block in Bytes [B] ]
CUDA Device:0_ has [ 2] .asyncEngineCount [ a number of asynchronous engines ]
POTS电话服务以前基于同步的固定延迟开关(70年代晚期,全球范围内逐渐合并了无法同步的频位数字分层网络,包括日本PDH标准、大陆PDH-E3互联运营商标准以及美国PDH-T3运营商服务,这终于避免了许多国际运营商服务抖动/失步/(重新)-同步风暴和掉线引起的头痛问题)
SDH/SONET-STM1 / 4 / 16,搭载在155 / 622 / 2488 [Mb/s]同步复用电路上。
SDH的美妙之处在于全球强制执行的时钟对齐框架结构,既确定性又稳定。
这使得较低级别容器数据流组件可以简单地进行存储器映射(交叉连接开关),从传入的STMx复制到SDH交叉连接上的传出STMx/PDHy有效载荷(记住,这还只是70年代晚期,因此CPU性能和DRAM处理GHz和ns都需要数十年)。这样一种盒中盒中盒的有效负载映射提供了硬件低开销,并在时间域中也提供了一些重新对齐的手段(在盒子之间有一些位间隙,以提供一些弹性,在标准给定最大时间偏移下)
虽然可能很难用几个词来解释这个概念的美妙之处,但AT&T和其他主要全球运营商非常喜欢SDH同步性和全球同步的SDH网络以及本地Add-Drop-MUX映射的美丽。
说了这个之后,
延迟控制设计
关注以下问题:
- 访问延迟:第一个位到达需要多长时间:[s]
- 传输带宽:每个单位时间可以传输/交付多少位:[b/s]
- 数据量:要传输的总位数:[b]
- 传输持续时间:需要多少单位时间
- ___________________:将整个数据量移动/交付给请求方需要多长时间:[s]
DAT磁带的马车的可爱例子:o),但你的BANDWIDTH术语引起了麻烦。带宽应该与时间有关(你的单位[kbit/s]证实了这一点)。那么你期望马车具有高带宽-即如何在最短的时间内从马车中获取大量数据?数据的VOLUME([{G|T|P|E}B])既不能说明BANDWIDTH也不能说明LATENCY。高延迟意味着即使是第一个比特,你也必须等待很长时间,而不管访问通道的BANDWIDTH(流)是否可能。 - user3666197DATA VOLUME中的z-[PB]的货车,则应部署一个带有至少6GB/s BANDWITH的系统,以便在不到 x-[DAY]s 的时间内读取它。 - user3666197