我有一些从Word生成的丑陋HTML,我想剥离其中所有的HTML注释。
HTML的样子是这样的:
HTML的样子是这样的:
<!--[if gte mso 9]><xml> <o:OfficeDocumentSettings> <o:RelyOnVML/> <o:AllowPNG/> </o:OfficeDocumentSettings> </xml><![endif]--><!--[if gte mso 9]><xml> <w:WordDocument> <w:View>Normal</w:View> <w:Zoom>0</w:Zoom> <w:TrackMoves/> <w:TrackFormatting/> <w:HyphenationZone>21</w:HyphenationZone> <w:PunctuationKerning/> <w:ValidateAgainstSchemas/> <w:SaveIfXMLInvalid>false</w:SaveIfXMLInvalid> <w:IgnoreMixedContent>false</w:IgnoreMixedContent> <w:AlwaysShowPlaceholderText>false</w:AlwaysShowPlaceholderText> <w:DoNotPromoteQF/> <w:LidThemeOther>NO-BOK</w:LidThemeOther> <w:LidThemeAsian>X-NONE</w:LidThemeAsian> <w:LidThemeComplexScript>X-NONE</w:LidThemeComplexScript> <w:Compatibility> <w:BreakWrappedTables/> <w:SnapToGridInCell/> <w:WrapTextWithPunct/> <w:UseAsianBreakRules/> <w:DontGrowAutofit/> <w:SplitPgBreakAndParaMark/> <w:EnableOpenTypeKerning/> <w:DontFlipMirrorIndents/> <w:OverrideTableStyleHps/> </w:Compatibility> <m:mathPr> <m:mathFont m:val="Cambria Math"/> <m:brkBin m:val="before"/> <m:brkBinSub m:val="--"/> <m:smallFrac m:val="off"/> <m:dispDef/> <m:lMargin m:val="0"/> <m:rMargin m:val="0"/> <m:defJc m:val="centerGroup"/> <m:wrapIndent m:val="1440"/> <m:intLim m:val="subSup"/> <m:naryLim m:val="undOvr"/> </m:mathPr></w:WordDocument> </xml><![endif]-->
..而我正在使用的正则表达式是这个
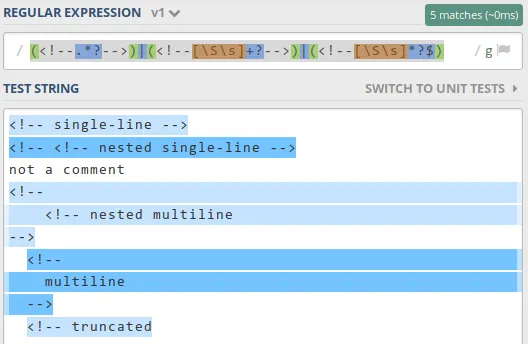
html = html.replace(/<!--(.*?)-->/gm, "")
但是似乎没有匹配项,字符串保持不变。
我错过了什么?