我正在探索 Kafka 是否支持优先级以处理任何队列或消息的事实。
看起来它不支持这样的功能。我通过谷歌搜索找到了这个邮件归档,支持这一点:http://mail-archives.apache.org/mod_mbox/incubator-kafka-users/201206.mbox/%3CCAOeJiJhVHsr=d6aSTihPsqWVg6vK5xYLam6yMDcd6UAUoXf-DQ@mail.gmail.com%3E
是否有人在这里配置了 Kafka 以优先考虑某个主题或消息?
我正在探索 Kafka 是否支持优先级以处理任何队列或消息的事实。
看起来它不支持这样的功能。我通过谷歌搜索找到了这个邮件归档,支持这一点:http://mail-archives.apache.org/mod_mbox/incubator-kafka-users/201206.mbox/%3CCAOeJiJhVHsr=d6aSTihPsqWVg6vK5xYLam6yMDcd6UAUoXf-DQ@mail.gmail.com%3E
是否有人在这里配置了 Kafka 以优先考虑某个主题或消息?
Kafka是一种快速、可扩展的分布式日志系统,其设计具有分区和复制的特性。因此,在主题或消息上没有优先级。
我也遇到过你所面临的相同问题。解决方案非常简单:在Kafka队列中创建主题,例如:
high_priority_queue
medium_priority_queue
low_priority_queue
将高优先级消息发布到high_priority_queue,将中等优先级消息发布到medium_priority_queue。现在,您可以创建Kafka消费者并为所有主题打开流。
// this is scala code
val props = new Properties()
props.put("group.id", groupId)
props.put("zookeeper.connect", zookeeperConnect)
val config = new ConsumerConfig(props)
val connector = Consumer.create(config)
val topicWithStreamCount = Map(
"high_priority_queue" -> 1,
"medium_priority_queue" -> 1,
"low_priority_queue" -> 1
)
val streamsMap = connector.createMessageStreams(topicWithStreamCount)
你可以获得每个主题的流。现在,如果高优先级主题没有任何消息,那么可以首先阅读中优先级队列的主题,如果中优先级队列为空,则阅读低优先级队列。
这个技巧对我很有效,可能对你也有帮助!
Confluent有一篇博客介绍如何在Apache Kafka中实现消息优先级,Implementing Message Prioritization in Apache Kafka。首先,重要的是要理解Kafka的设计不允许开箱即用地解决消息优先级问题,主要原因是:
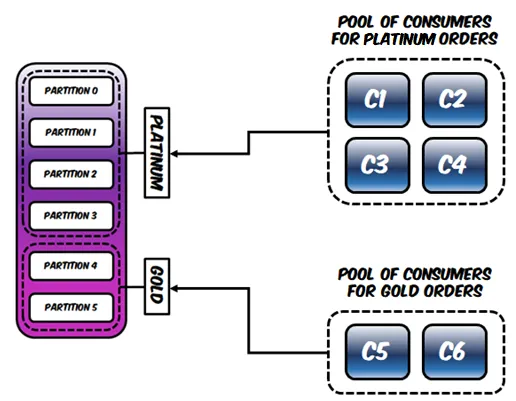
提出的解决方案是使用Bucket Priority Pattern,该模式可在GitHub上获得,并可通过自定义生产者的分区器和消费者的分配策略,在单个主题中使用多个分区而不是使用多个主题来处理不同的优先级。
基于消息键,生产者将将消息写入正确的优先级桶中:

消费者组将自定义其分配策略,并优先读取具有最高分区的消息:
在客户端代码(生产者和消费者)中,您需要启动并调整以下客户端配置。
# Producer
configs.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG,
BucketPriorityPartitioner.class.getName());
configs.setProperty(BucketPriorityConfig.BUCKETS_CONFIG, "Platinum, Gold");
configs.setProperty(BucketPriorityConfig.ALLOCATION_CONFIG, "70%, 30%");
# Consumer
configs.setProperty(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,
BucketPriorityAssignor.class.getName());
configs.setProperty(BucketPriorityConfig.BUCKETS_CONFIG, "Platinum, Gold");
configs.setProperty(BucketPriorityConfig.ALLOCATION_CONFIG, "70%, 30%");
0 < 1 < ... < N-1
PriorityKafkaProducer(实现org.apache.kafka.clients.producer.Producer):Future<RecordMetadata> send(int priority, ProducerRecord<K, V> record)。这表示在该优先级级别上产生记录。Future<RecordMetadata> send(int priority, ProducerRecord<K, V> record)将默认记录产生在最低优先级级别0上。对于每个逻辑主题XYZ - 优先级级别0 <= i XYZ-i支持
CapacityBurstPriorityKafkaConsumer(实现org.apache.kafka.clients.consumer.Consumer):XYZ-i。这与PriorityKafkaProducer一起工作。
max.poll.records属性根据maxPollRecordsDistributor - 默认为ExpMaxPollRecordsDistributor在优先级主题使用者之间拆分。其余的KafkaConsumer配置原样传递给每个优先级主题使用者。在定义max.partition.fetch.bytes,fetch.max.bytes和max.poll.interval.ms时必须小心,因为这些值将在所有优先级主题使用者中使用。max.poll.records属性分配到每个优先级主题使用者中作为其保留容量的思想来工作。从配置了分布式max.poll.records值的所有优先级级别主题使用者中按顺序获取记录。分配必须向更高的优先级预留更高的容量或处理速率。max.poll.records并不受限于基于maxPollRecordsDistributor的保留容量,否则整体容量将被浪费。poll()的最后max.poll.history.window.size次尝试中,至少min.poll.window.maxout.threshold次接收到等于分配的max.poll.records的记录数,该记录数是基于maxPollRecordsDistributor分配的。这表明该分区有更多的传入记录要处理。poll()的最后max.poll.history.window.size次尝试中最小未使用容量。我会在这里添加@Sky的答案的Java版本供大家参考。注意:我没有使用KafkaStreams,而是使用了普通的KafkaConsumer进行实现。
从生产者的角度来看,您可以根据优先级将消息发布到相应的主题中。
从消费者的角度来看,您可以尝试实现以下内容。请注意,这不是一个可用于生产环境的实现。此解决方案是单线程的,可能会很慢。
与桶优先级模式不同,此代码将继续处理来自高优先级主题的消息,直到所有消息都被处理完毕。当高优先级主题上没有消息时,它将回退到下一个优先级,以此类推。
import lombok.*;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.context.event.ApplicationReadyEvent;
import org.springframework.context.event.EventListener;
import org.springframework.stereotype.Component;
import java.util.function.Consumer;
import javax.annotation.PostConstruct;
import java.time.Duration;
import java.util.*;
@Component
@Slf4j
public class PriorityBasedConsumer {
@Value("${spring.kafka.consumer.group-id}")
private String consumerGroupId;
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
private final List<TopicConsumer> consumersInPriorityOrder = new ArrayList<>();
@RequiredArgsConstructor(staticName = "of")
@Getter
private static class TopicConsumer {
private final String topic;
private final KafkaConsumer<String, String> kafkaConsumer;
private final Consumer<ConsumerRecords<String, String>> consumerLogic;
}
private void highPriorityConsumer(ConsumerRecords<String, String> records) {
// high priority processing...
}
private void mediumPriorityConsumer(ConsumerRecords<String, String> records) {
// medium priority processing...
}
private void lowPriorityConsumer(ConsumerRecords<String, String> records) {
// low priority processing...
}
@PostConstruct
public void init() {
Map<String, Consumer<ConsumerRecords<String, String>>> topicVsConsumerLogic = new HashMap<>();
topicVsConsumerLogic.put("high_priority_queue", this::highPriorityConsumer);
topicVsConsumerLogic.put("medium_priority_queue", this::mediumPriorityConsumer);
topicVsConsumerLogic.put("low_priority_queue", this::lowPriorityConsumer);
// if you're taking the topic names from external configuration, make sure to order it based on priority.
for (String topic : Arrays.asList("high_priority_queue", "medium_priority_queue", "low_priority_queue")) {
Properties consumerProperties = new Properties();
consumerProperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
consumerProperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
consumerProperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
consumerProperties.put(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
// add other properties.
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProperties);
consumer.subscribe(Collections.singletonList(topic));
consumersInPriorityOrder.add(TopicConsumer.of(topic, consumer, topicVsConsumerLogic.get(topic)));
}
}
@EventListener(ApplicationReadyEvent.class) // To execute once the application is ready.
public void startConsumers() {
// For illustration purposes, I just wrote this synchronous code. Use thread pools where ever
// necessary for high performance.
while (true) { // poll infinitely
try {
// Consumers iterated based on priority.
for (TopicConsumer topicConsumer : consumersInPriorityOrder) {
ConsumerRecords<String, String> records
= topicConsumer.getKafkaConsumer().poll(Duration.ofMillis(100));
if (!records.isEmpty()) {
topicConsumer.getConsumerLogic().accept(records);
break; // To start consuming again based on priority.
}
}
} catch (Exception e) {
// on any unknown runtime exceptions, ignoring here. You can add your proper logic.
log.error("Unknown exception occurred.", e);
}
}
}
}