为什么以下正则表达式在Javascript中通过捕获组可以捕获字符串“abc”,但在PCRE中不能(尽管它仍然会匹配)?
(.*)*
(.*)*
Initial state
(.*)* abc
^ ^
First, the (.*) part is matched against abc, and the input position is advanced to the end. The capture group contains abc at this point.
(.*)* abc
^ ^
Now, the input position is after the c character, the remaining input is the empty string. The Kleene star initiates a second attempt at matching the (.*) group:
(.*)* abc
^ ^
The (.*) group matches the empty string after abc. Since it matched, the previously captured string is overwritten.
Since the input position hasn't advanced, the * ends iterating there and the match succeeds.
$ pcretest
PCRE version 8.39 2016-06-14
re> /(.*)*/
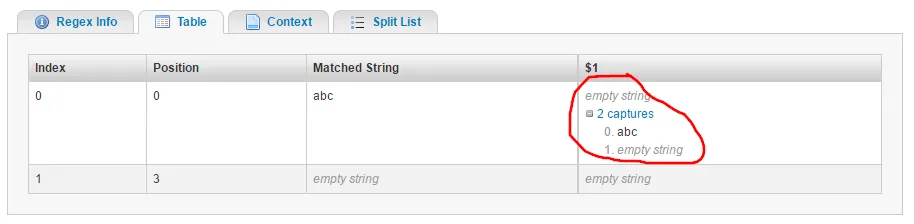
data> abc
0: abc
1:
$ perl -e '"abc" =~ /(.*)*/; print "<$&> <$1>\n";'
<abc> <>
让我们将其与.NET进行比较, 它具有相同的行为,但支持多个捕获:
关于JavaScript:
以下是ECMA-262 §21.2.2.5.1运行时语义:RepeatMatcher抽象操作:
抽象操作 RepeatMatcher 接收八个参数:匹配器 m、整数 min、整数(或 ∞)max、布尔值 greedy、状态 x、继续项 c、整数 parenIndex 和整数 parenCount,执行以下步骤:RepeatMatcher 是处理匹配内部操作 m 的操作。状态是有序对(
endIndex,captures),其中endIndex是整数,而捕获则是NcapturingParens值的列表。状态用于表示正则表达式匹配算法中的部分匹配状态。endIndex是到目前为止模式匹配的最后一个输入字符的索引加一,而captures保存捕获括号的结果。captures的第n个元素是List,表示第n个捕获括号集合获得的值,或者如果尚未到达第n个捕获括号集,则为undefined。由于回溯,许多状态在匹配过程中任何时间都可能在使用。
对于你的例子,RepeatMatcher 的参数如下:
m: 负责处理子模式(.*)的匹配器(Matcher)min: 0(Kleene星号量词的最小匹配次数)max: ∞(Kleene星号量词的最大匹配次数)greedy: true(使用贪婪模式的Kleene星号量词)x: (0, [undefined])(请参见上述状态定义)c: 在此处,它是:一个继续函数,它总是将其状态参数作为成功的MatchResult返回,同时折叠父规则parenIndex: 0(根据§21.2.2.5,这是整个正则表达式中在此产生物左侧出现的左括号数量)parenCount: 1(同一规范段落,这是此产生物的Atom扩展中左捕获括号的数量 - 我不会在这里粘贴完整的规范,但这基本上意味着m定义了一个捕获组)规范中的正则表达式匹配算法是以传递续集风格为基础定义的。基本上,这意味着c操作表示接下来会发生什么。
让我们展开这个算法。
在第一次迭代中,x1状态为(0,[undefined])。
max 不为零d1,它将在第二次遍历中使用,因此稍后我们会回到这个闭包。cap1cap1 中的捕获重置为 undefined,这在第一遍遍历中是一个无操作e1 = 0xr1 = (e1, cap1)min 为零,跳过此步骤greedy 为真,跳过此步骤z1 = m(xr, d1) - 这将评估子模式 (.*)m将使用(.*)匹配abc,然后调用我们的d1闭包,所以让我们展开它。
d1使用状态y1 =(3, ["abc"])进行评估:
min为0,但y1的endIndex为3且x1的endIndex为0,因此不返回failuremin2 = min = 0,因为min = 0max2 = max = ∞,因为max = ∞RepeatMatcher(m, min2, max2, greedy, y, c, parenIndex, parenCount)并返回其结果。即:RepeatMatcher(m,0,∞,false,y1,c,0,1)现在我们要进行第二次迭代,其中 x2= y1=(3,["abc"])。
max 不为零d2["abc"],得到 cap2cap2 中的捕获重置为undefined,得到 cap2 = [undefined]e2 = 3xr2 = (e2, cap2)min 为零,跳过此步骤greedy 为真,跳过此步骤令 z2 = m(xr2, d2) - 这会计算子模式 (.*)
这次 m 匹配了 abc 后面的空字符串,并调用我们的 d2 闭包。让我们评估 d2 的行为。它的参数是 y2 = (3, [""])
min 仍然为零,但 y2 的 endIndex 是 3,x2 的 endIndex 也是 3(请记住这次 x 是上一次迭代中的 y 状态),闭包简单地返回 failure。
z2 是 failure,跳过此步骤c(x2),在本次迭代中为 c((3, ["abc"]))。c在这里仅返回一个有效的MatchResult,因为我们已经到达模式的末尾。这意味着d1返回此结果,并且第一次迭代从步骤10传递它。
基本上,正如您所看到的,导致JS行为与PCRE不同的规范行是以下行:
a. 如果
min为零且y的endIndex等于x的endIndex,则返回failure。
与以下内容组合时:
- 调用
c(x)并返回其结果。
如果迭代失败,则返回先前捕获的值。
(.*){2}并强制进行第二次匹配,那么行为就与Perl相匹配。 - Tim Angusperl -E'say "\@$-[0]: $&" while "abc" =~ /.*?/g'演示了在同一位置匹配空字符串和非空字符串。正如我上面所说的,当匹配与前一个匹配的位置和长度相同时,Perl会添加一个字符。 - ikegami
(.*)*。在PCRE中,将Kleene星号放在末尾会阻止捕获组起作用。至少根据regex101的说法是这样的。我是否在这个特定的正则表达式测试器中漏掉了什么? - Tim Angus(.+)+,它会按照我的预期工作。 - Tim Angus*改为+可以使模式至少匹配 1 个字符。这个问题和许多其他问题一样,其根本原因在于 JS 正则表达式处理空匹配的方式。请参见 Some regex pattern is breaking the javascript regex engine。 - Wiktor Stribiżew