更新:我已将原始问题转移到https://codereview.stackexchange.com/questions/127055/building-tree-graph-from-dictionary-performance-issues
以下是简短的版本,没有代码。
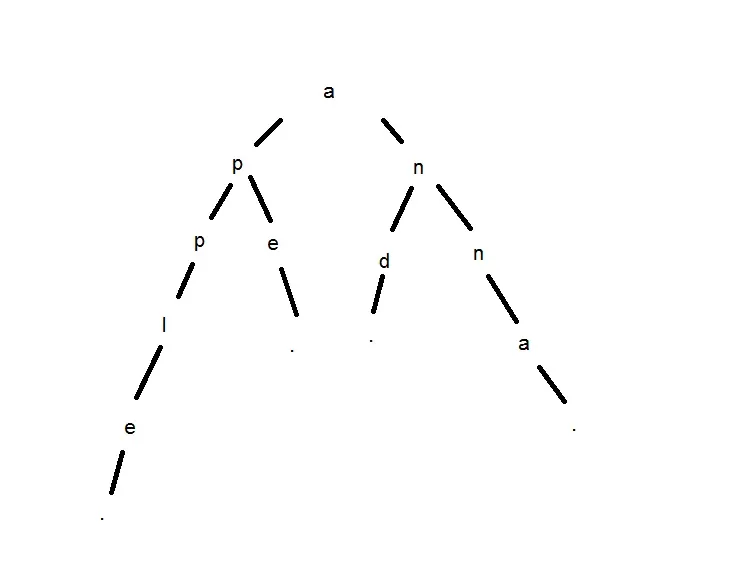
我试图从字典中构建前缀树。所以,使用以下字典'and','anna','ape','apple',图应该看起来像这样:
 我尝试了两种方法:使用关联数组和使用自编写的树/节点类。
我尝试了两种方法:使用关联数组和使用自编写的树/节点类。
注意:原始字典大约有8 MB,并包含> 600000个单词。
问题:有没有一种好(快/高效)的方法来完成这项工作?
到目前为止,我已经尝试过:
php关联数组(它们对于将来在此图上的工作不太灵活)。
自编写的Tree / Node类(性能问题 - 执行时间最多增加7倍,即使没有实现除“插入”函数之外的任何内容,内存使用量也增加了2倍)。
示例代码可在codereview上找到(问题中的第一个链接)。