我的问题:
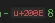
我有一个使用.NET编写的应用程序,通过电子邮件发送新闻通讯。当在Outlook中查看新闻时,Outlook会显示一个问号,代替无法识别的隐藏字符。这些隐藏字符来自将构成新闻通讯的HTML复制并粘贴到表单中提交的终端用户。C#的trim()函数将从字符串开头或结尾处移除这些隐藏字符。当在Gmail中查看新闻时,Gmail会很好地忽略它们。将这些隐藏字符粘贴到Word文档中并打开“显示段落标记和隐藏符号”选项后,这些符号会显示为一个矩形内部的另一个矩形。此外,构成新闻通讯的文本可以是任何语言,因此必须接受Unicode字符。我已经尝试循环遍历字符串以检测字符,但循环无法识别它并跳过它。要求终端用户先将HTML粘贴到记事本中再提交是行不通的。
我的问题:
如何使用C#检测和消除这些隐藏字符?
我有一个使用.NET编写的应用程序,通过电子邮件发送新闻通讯。当在Outlook中查看新闻时,Outlook会显示一个问号,代替无法识别的隐藏字符。这些隐藏字符来自将构成新闻通讯的HTML复制并粘贴到表单中提交的终端用户。C#的trim()函数将从字符串开头或结尾处移除这些隐藏字符。当在Gmail中查看新闻时,Gmail会很好地忽略它们。将这些隐藏字符粘贴到Word文档中并打开“显示段落标记和隐藏符号”选项后,这些符号会显示为一个矩形内部的另一个矩形。此外,构成新闻通讯的文本可以是任何语言,因此必须接受Unicode字符。我已经尝试循环遍历字符串以检测字符,但循环无法识别它并跳过它。要求终端用户先将HTML粘贴到记事本中再提交是行不通的。
我的问题:
如何使用C#检测和消除这些隐藏字符?