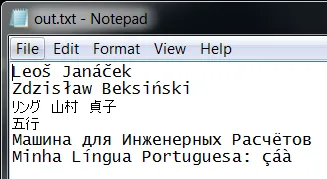
愉快的例子:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
czech = u'Leoš Janáček'.encode("utf-8")
print(czech)
pl = u'Zdzisław Beksiński'.encode("utf-8")
print(pl)
jp = u'リング 山村 貞子'.encode("utf-8")
print(jp)
chinese = u'五行'.encode("utf-8")
print(chinese)
MIR = u'Машина для Инженерных Расчётов'.encode("utf-8")
print(MIR)
pt = u'Minha Língua Portuguesa: çáà'.encode("utf-8")
print(pt)
不满意的输出:
b'Leo\xc5\xa1 Jan\xc3\xa1\xc4\x8dek'
b'Zdzis\xc5\x82aw Beksi\xc5\x84ski'
b'\xe3\x83\xaa\xe3\x83\xb3\xe3\x82\xb0 \xe5\xb1\xb1\xe6\x9d\x91 \xe8\xb2\x9e\xe5\xad\x90'
b'\xe4\xba\x94\xe8\xa1\x8c'
b'\xd0\x9c\xd0\xb0\xd1\x88\xd0\xb8\xd0\xbd\xd0\xb0 \xd0\xb4\xd0\xbb\xd1\x8f \xd0\x98\xd0\xbd\xd0\xb6\xd0\xb5\xd0\xbd\xd0\xb5\xd1\x80\xd0\xbd\xd1\x8b\xd1\x85 \xd0\xa0\xd0\xb0\xd1\x81\xd1\x87\xd1\x91\xd1\x82\xd0\xbe\xd0\xb2'
b'Minha L\xc3\xadngua Portuguesa: \xc3\xa7\xc3\xa1\xc3\xa0'
如果我像这样打印它们:
jp = u'リング 山村 貞子'
print(jp)
我理解为:
Traceback (most recent call last):
File "x.py", line 5, in <module>
print(jp)
File "C:\Python34\lib\encodings\cp850.py", line 19, in encode
return codecs.charmap_encode(input,self.errors,encoding_map)[0]
UnicodeEncodeError: 'charmap' codec can't encode characters in position
0-2: character maps to <undefined>
我还尝试了这个问题中提到的以下方法(以及其他涉及sys.stdout.encoding的替代方法):
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import print_function
import sys
def safeprint(s):
try:
print(s)
except UnicodeEncodeError:
if sys.version_info >= (3,):
print(s.encode('utf8').decode(sys.stdout.encoding))
else:
print(s.encode('utf8'))
jp = u'リング 山村 貞子'
safeprint(jp)
并且事情变得更加神秘:
リング 山村 貞子
那么,Python 3.4、Unicode、不同的语言和Windows有什么关系呢?我找到的几乎所有可能的示例都与Python 2.x有关。
是否存在一种通用和跨平台的方法,在Python 3.4中以良好且非恶心的方式打印任何语言的任何Unicode字符?
编辑:
我尝试在终端输入:
chcp 65001
要更改代码页,可以像这里和评论中提出的那样尝试,但是并没有成功(包括使用sys.stdout.encoding的尝试)。
WriteConsoleW,但Python没有使用它,详见https://bugs.python.org/issue1602。 - Philipp