我需要构建一个算法(不一定有效),给定一个字符串,找到并打印出两个相同的子序列(打印指着色,例如)。此外,这两个子序列的索引集合的并集必须是连续自然数集合(整数的完整段)。
在数学上,我正在寻找的东西称为“紧密双胞胎”,如果有帮助的话。(例如,请参见此处的论文(PDF)。)
让我举几个例子:
1)考虑字符串231213231
它有两个我要找的形式为“123”的子序列。要更好地看到它,请查看此图像:
在数学上,我正在寻找的东西称为“紧密双胞胎”,如果有帮助的话。(例如,请参见此处的论文(PDF)。)
让我举几个例子:
1)考虑字符串231213231
它有两个我要找的形式为“123”的子序列。要更好地看到它,请查看此图像:
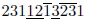
第一个子序列用下划线标记,第二个用上划线标记。你可以看到它们具备我需要的所有属性。
2)考虑字符串12341234。
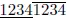
3)考虑字符串12132344。
现在情况变得更加复杂:
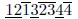
4)考虑字符串:13412342
这也不是那么容易的:
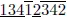
我认为这些示例已经很好地解释了我的意思。
我已经想了很长时间,想要编写一个能够实现这一点的算法,但是没有成功。
对于着色,我想使用这段代码:
using namespace std;
HANDLE hConsole;
hConsole = GetStdHandle(STD_OUTPUT_HANDLE);
SetConsoleTextAttribute(hConsole, k);
其中k代表颜色。
任何帮助,即使是提示,都将不胜感激。