我进行了大量的数学计算,以计算在一个范围内双胞胎素数(twin prime)的数量,并将任务分配给多个线程。
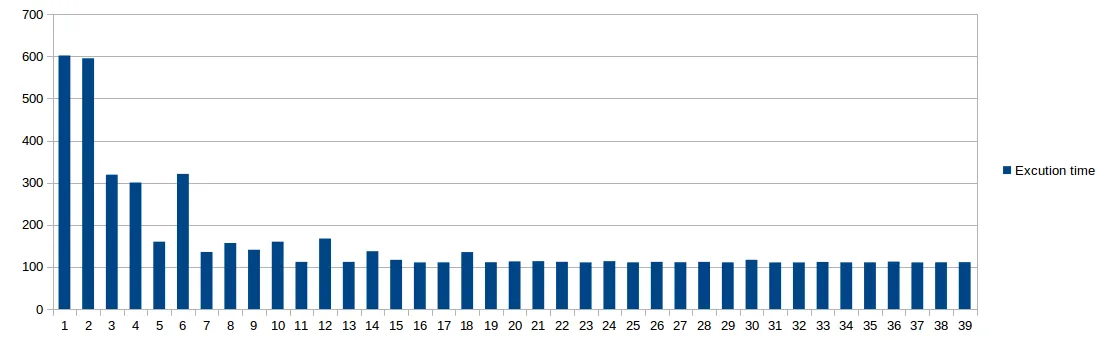
下面是关于执行时间与线程数之间关系的概述。
我的问题涉及以下方面:
为什么单线程和双线程的性能非常相似?
为什么当使用5或7个线程时,执行时间会下降,而使用6或8个线程时,执行时间会增加?(在多次测试中我都有这种经验。)
我使用的是一台8核电脑。我能否声称2×n(其中n是核数)是一个好的线程数规则?
如果我使用大量RAM的代码,我是否可以期望在此性能概览中看到类似的趋势,或者随着线程数量的增加它是否会发生显著变化?
这是代码的主要部分,仅用于展示它不会占用太多的RAM。
bool is_prime(long a)
{
if(a<2l)
return false;
if(a==2l)
return true;
for(long i=2;i*i<=a;i++)
if(a%i==0)
return false;
return true;
}
uint twin_range(long l1,long l2,int processDiv)
{
uint count=0;
for(long l=l1;l<=l2;l+=long(processDiv))
if(is_prime(l) && is_prime(l+2))
{
count++;
}
return count;
}
规格:
$ lsb_release -a
Distributor ID: Ubuntu
Description: Ubuntu 16.04.1 LTS
Release: 16.04
Codename: xenial
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 94
Model name: Intel(R) Core(TM) i7-6700 CPU @ 3.40GHz
Stepping: 3
CPU MHz: 799.929
CPU max MHz: 4000.0000
CPU min MHz: 800.0000
BogoMIPS: 6815.87
Virtualisation: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 8192K
NUMA node0 CPU(s): 0-7
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch intel_pt tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp
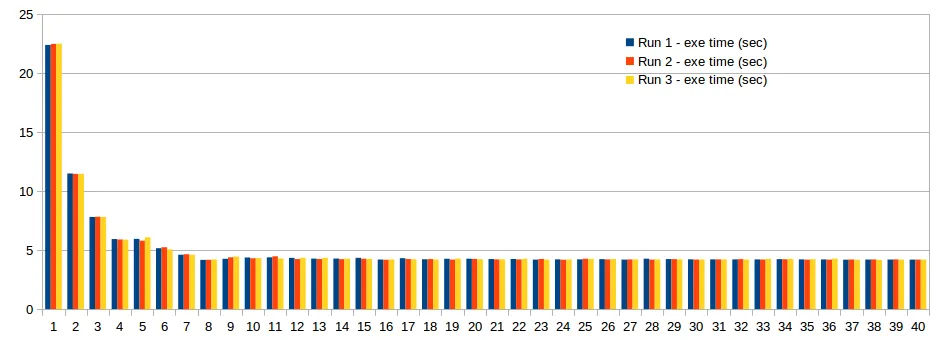
更新(接受答案后)
新个人资料:
bool is_prime(long a)
{
if(a<2l)
return false;
if(a==2l)
return true;
for(long i=2;i*i<=a;i++)
if(a%i==0)
return false;
return true;
}
void twin_range(long n_start,long n_stop,int index,int processDiv)
{
// l1+(0,1,...,999)+0*1000
// l1+(0,1,...,999)+1*1000
// l1+(0,1,...,999)+2*1000
// ...
count=0;
const long chunks=1000;
long r_begin=0,k=0;
for(long i=0;r_begin<=n_stop;i++)
{
r_begin=n_start+(i*processDiv+index)*chunks;
for(k=r_begin;(k<r_begin+chunks) && (k<=n_stop);k++)
{
if(is_prime(k) && is_prime(k+2))
{
count++;
}
}
}
std::cout
<<"Thread "<<index<<" finished."
<<std::endl<<std::flush;
return count;
}