问题
我有一组人,我希望每个人都与这个组中的其他人进行1:1会面。一个人一次只能与另一个人见面,因此我想要做到以下几点:
- 找到所有可能的配对组合
- 将配对组合分组为“轮次”会议,其中每个人只能参加一次,而且每个轮次应包含尽可能多的配对以满足在最少轮次内的所有可能配对组合。
为了演示所需输入/输出的问题,请假设我有以下列表:
>>> people = ['Dave', 'Mary', 'Susan', 'John']
我想要生成以下输出:
>>> for round in make_rounds(people):
>>> print(round)
[('Dave', 'Mary'), ('Susan', 'John')]
[('Dave', 'Susan'), ('Mary', 'John')]
[('Dave', 'John'), ('Mary', 'Susan')]
如果我有奇数个人,那么我会期望得到这个结果:
>>> people = ['Dave', 'Mary', 'Susan']
>>> for round in make_rounds(people):
>>> print(round)
[('Dave', 'Mary')]
[('Dave', 'Susan')]
[('Mary', 'Susan')]
这个问题的关键是我需要我的解决方案具有较好的性能(在合理范围内)。我已经编写了可以使用的代码,但随着 people 的大小增长,它变得指数级缓慢。我不知道足够有效率算法的编写,无法确定我的代码是否低效,或者是否仅受问题参数的限制。
我尝试过的方法
第一步很容易:我可以使用 itertools.combinations 获取所有可能的配对:
>>> from itertools import combinations
>>> people_pairs = set(combinations(people, 2))
>>> print(people_pairs)
{('Dave', 'Mary'), ('Dave', 'Susan'), ('Dave', 'John'), ('Mary', 'Susan'), ('Mary', 'John'), ('Susan', 'John')}
为了计算轮次,我按以下方式建立轮次:
- 创建一个空的
round列表 - 迭代使用上面的
combinations方法计算的people_pairs集合的副本 - 对于每个人,检查当前
round中是否存在包含该个体的任何现有配对 - 如果已经存在包含其中一个个体的配对,则跳过此轮的该配对。如果不存在,则将该配对添加到该轮中,并从
people_pairs列表中删除该配对。 - 一旦所有人员配对都进行了迭代,就将该轮追加到主要的
rounds列表中 - 再次开始,因为
people_pairs现在仅包含未进入第一轮的配对
最终这样就能得到所需的结果,并且将我的人员配对缩减到没有剩余而所有轮次都计算出来了。我已经可以看到这需要大量迭代,但是我不知道有更好的方法。
这是我的代码:
from itertools import combinations
# test if person already exists in any pairing inside a round of pairs
def person_in_round(person, round):
is_in_round = any(person in pair for pair in round)
return is_in_round
def make_rounds(people):
people_pairs = set(combinations(people, 2))
# we will remove pairings from people_pairs whilst we build rounds, so loop as long as people_pairs is not empty
while people_pairs:
round = []
# make a copy of the current state of people_pairs to iterate over safely
for pair in set(people_pairs):
if not person_in_round(pair[0], round) and not person_in_round(pair[1], round):
round.append(pair)
people_pairs.remove(pair)
yield round
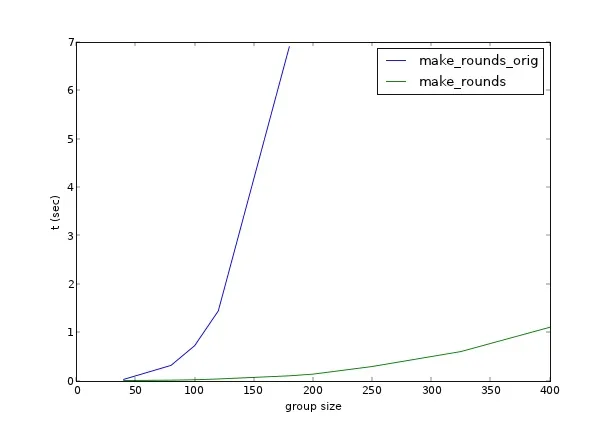
使用 https://mycurvefit.com 绘制出该方法对列表大小为100-300的性能表现,结果显示计算1000人名单的回合可能需要大约100分钟。是否有更有效的方法?
注意:我实际上并不想组织1000人的会议 :) 这只是一个简单的例子,代表我要解决的匹配/组合问题。