使用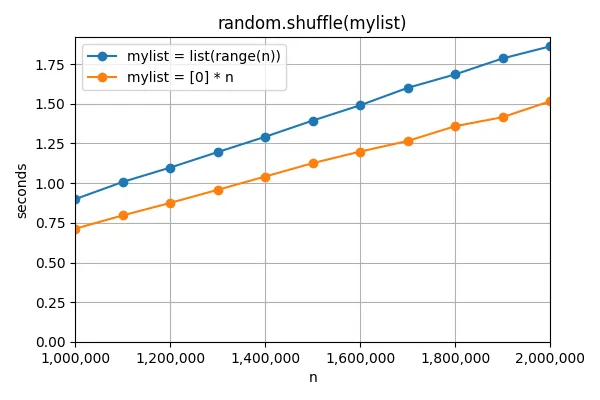 为什么打乱
为什么打乱
我还尝试了使用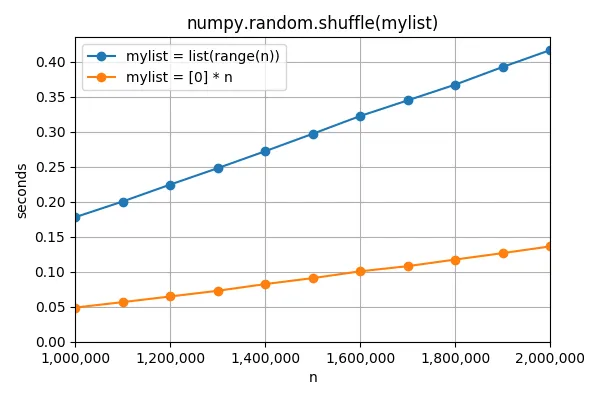 我还尝试了第三种重新排列列表元素的方法,即
我还尝试了第三种重新排列列表元素的方法,即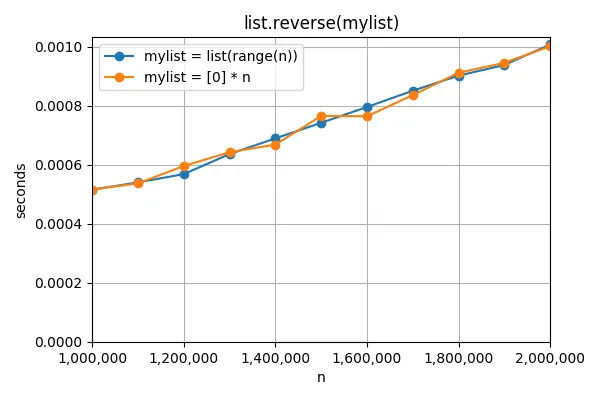 以防打乱顺序很重要,我也尝试了在打乱列表后使用
以防打乱顺序很重要,我也尝试了在打乱列表后使用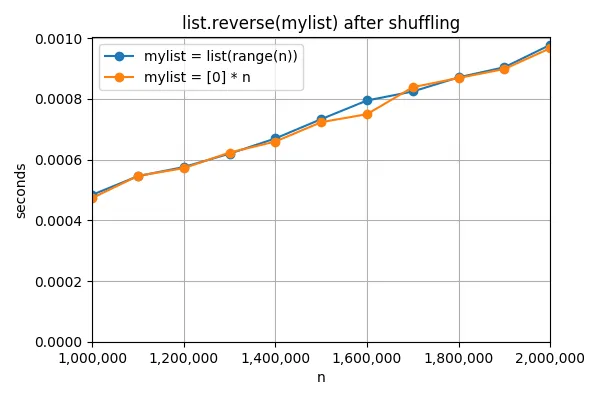 那么有什么不同呢?打乱和翻转都只需要重新排列列表内部的指针,为什么对象对于打乱而非翻转有影响?
那么有什么不同呢?打乱和翻转都只需要重新排列列表内部的指针,为什么对象对于打乱而非翻转有影响?
以下是我的基准测试代码:
random.shuffle函数,我发现对于需要打乱的列表list(range(n)),打乱所需的时间比打乱[0] * n的时间多大约25%。以下是在n大小从100万到200万时的时间统计:
为什么打乱list(range(n))会更慢?和排序一个列表(需要查看对象)或复制一个列表(增加了对象内部的引用计数)不同,这里不应该考虑对象。这应该只是重新排列列表内部的指针。我还尝试了使用
numpy.random.shuffle函数,其中打乱list(range(n))比打乱[0] * n慢3倍(!):
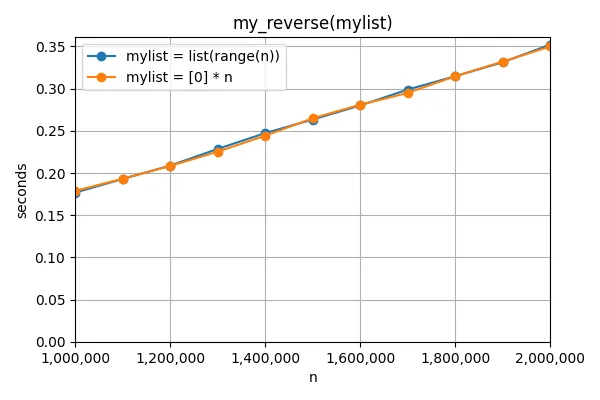
我还尝试了第三种重新排列列表元素的方法,即list.reverse。结果对于两个列表来说都需要相同的时间:
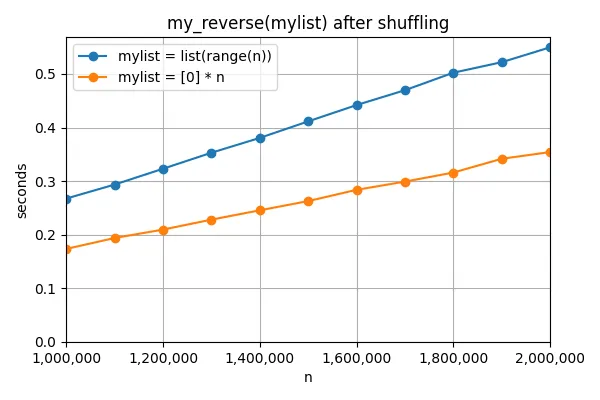
以防打乱顺序很重要,我也尝试了在打乱列表后使用list.reverse。同样,对于两个列表来说都需要相同的时间,并且与之前未进行打乱时所需时间相同:
那么有什么不同呢?打乱和翻转都只需要重新排列列表内部的指针,为什么对象对于打乱而非翻转有影响?以下是我的基准测试代码:
import random
import numpy
from timeit import repeat, timeit
from collections import defaultdict
shufflers = {
'random.shuffle(mylist)': random.shuffle,
'numpy.random.shuffle(mylist)': numpy.random.shuffle,
'list.reverse(mylist)': list.reverse,
}
creators = {
'list(range(n))': lambda n: list(range(n)),
'[0] * n': lambda n: [0] * n,
}
for shuffler in shufflers:
print(shuffler)
for creator in creators:
print(creator)
times = defaultdict(list)
for _ in range(10):
for i in range(10, 21):
n = i * 100_000
mylist = creators[creator](n)
# Uncomment next line for pre-shuffling
# numpy.random.shuffle(mylist)
time = timeit(lambda: shufflers[shuffler](mylist), number=1)
times[n].append(time)
s = '%.6f ' * len(times[n])
# Indent next line further to see intermediate results
print([round(min(times[n]), 9) for n in sorted(times)])
random.shuffle的源代码了吗? - DisappointedByUnaccountableMod