我曾经使用过多个音频程序,如SDL mixer、audacity等,但我想了解这些小型音频工具的内部结构。音频数据是如何被处理的等等。我还看到了一些用C++编写的MP3播放器的示例代码,它使用void*来处理音频数据。
但所有这些都没有帮助我理解计算机中音频是如何工作的。所以,有人能向我解释(或介绍一些书籍),计算机是如何存储和处理数字音频数据的吗?例如,如果将一个三角波形存储到.wav文件中,该波形会以什么样的位模式存储?
我曾经使用过多个音频程序,如SDL mixer、audacity等,但我想了解这些小型音频工具的内部结构。音频数据是如何被处理的等等。我还看到了一些用C++编写的MP3播放器的示例代码,它使用void*来处理音频数据。
但所有这些都没有帮助我理解计算机中音频是如何工作的。所以,有人能向我解释(或介绍一些书籍),计算机是如何存储和处理数字音频数据的吗?例如,如果将一个三角波形存储到.wav文件中,该波形会以什么样的位模式存储?
5, 18, 6, -4, -12, -3, 7, 14, 4
如果将这些数字作为点绘制在笛卡尔图上:样本值决定沿Y轴的位置,而样本的序列号(0、1、2、3等)则决定沿X轴的位置。X轴只是一个单调递增的数值线。波形的表示方法
在Audacity手册中有更详细的解释,音频是如何被表示的:
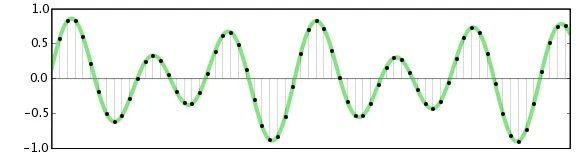
...每个垂直线的高度都表示为一个有符号的数字。
数字音频的更多信息
你可能会注意到所有这些链接都来自Audacity项目。这不是巧合。
以您提供的WAV文件为例:
一个WAV文件将会有一个头部,其中包含关键信息,向播放器或音频处理器指定了通道数、采样率、位深度、数据长度等。头部之后是原始比特模式,用于存储音频样本(如果您不知道什么是采样,请参考维基百科)。每个样本由若干字节组成(在头部中指定),并指定了波形在任何给定时间点上的振幅。每个样本可以以有符号或无符号形式存储(也在头部中指定)。
声音是一种复杂的现象。它通常是由空气(或其他介质)中的移动物体引起的,例如扬声器锥体来回运动。该运动反过来会引起空气压力变化,这些变化像池塘中的波浪一样穿过空气传播。我们的耳鼓将压力变化转换为大脑处理为声音的现象。
计算机使用麦克风而不是耳膜“听”声音。麦克风将压力变化转换成电位,其振幅对应于压力的强度。然后,计算机使用称为采样的技术处理电信号。计算机通过在规律间隔处测量其幅度来采样信号,通常每秒测量44,100次。每个测量值以固定精度存储,通常为16位。
计算机发出声音的方法与上述过程类似,只是更多或更少地颠倒了这个过程。样本被馈送到一个生成与样本值成比例的电位的设备中。然后,扬声器或其他类似设备可能会将电信号转换为空气压力变化。测量的速率称为采样率。常见的采样率是每秒44,100次(用于紧凑型光盘或CD音频)。数字音频数据集的比特率是每秒所需存储的位数。如果数据具有固定的采样率和精度(如CD音频),则比特率只是它们的乘积。例如,CD音频的一个通道的比特率为44,100个采样/秒×16位/采样= 705,600位/秒。比特率是存储的一般度量,不总是简单地是采样率和精度的乘积。例如,我们将讨论一种使用可变精度编码数据的方法。
希望对您有所帮助。