你没有提到你的操作系统,也没有提到你是如何创建zip文件的,但我还是设法重现了你的问题,在Windows 10上使用
7-Zip:
- 创建一个简单的文本文件,其中包含一些琐碎的内容(例如仅包含三个字符“abc”)。
- 将文件保存为D:\Temp\Aufhänge.txt。注意文件名中的umlaut。
- 在Windows文件浏览器中找到该文件。
- 选择该文件并右键单击。从上下文菜单中选择7-Zip>添加到“Aufhänge.zip”以创建Aufhänge.zip。
然后,在NetBeans中运行以下代码解压刚刚创建的文件:
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.nio.charset.Charset;
import java.util.zip.ZipEntry;
import java.util.zip.ZipInputStream;
public class GermanZip {
static String ZIP_PATH = "D:\\Temp\\Aufhänge.zip";
public static void main(String[] args) throws FileNotFoundException, IOException {
ZipInputStream zipInputStream = new ZipInputStream(new FileInputStream(ZIP_PATH), Charset.forName("UTF-8"));
ZipEntry zipEntry;
while ((zipEntry = zipInputStream.getNextEntry()) != null) {
System.out.println(zipEntry.getName());
}
}
}
正如您所指出的,当执行此语句时:
zipEntry = zipInputStream.getNextEntry()) != null,代码会抛出
java.lang.IllegalArgumentException: MALFORMED异常。
问题的原因是默认情况下
7-Zip使用Cp437编码对zip文件中的文件名进行编码,正如
来自7-Zip的此评论所述:
默认编码为OEM(DOS)编码。这是为了与旧版zip软件兼容。
这就是为什么使用
Charset.forName("Cp437")而不是
Charset.forName("UTF-8")时解压缩可以正常工作的原因。
如果您想要使用
Charset.forName("UTF-8")进行解压缩,则必须强制
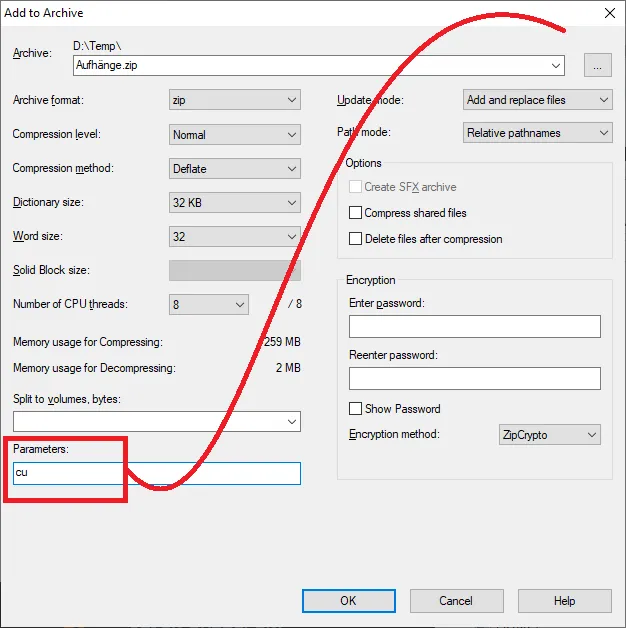
7-Zip将zip文件中的文件名编码为UTF-8。要做到这一点,请在运行
7-Zip时指定
cu参数,正如链接评论中所述:
此答案特定适用于Windows 10和7-Zip,但通用原则应适用于任何环境:如果为您的ZipInputStream指定UTF-8编码,请确保zip文件中的文件名确实使用UTF-8编码。您可以通过在二进制编辑器中打开zip文件并搜索压缩文件的名称来轻松验证此操作。
基于下面OP的评论/问题的更新:
很遗憾,
.ZIP文件格式规范目前没有提供一种存储除一个例外之外的压缩文件名编码的方法,该例外在“附录D-语言编码(EFS)”中描述:
D.2 如果通用位标志11未设置,则文件名和注释应符合原始的ZIP字符编码。如果通用位标志11已设置,则文件名和注释必须支持Unicode标准4.1.0或更高版本,使用UTF-8存储规范定义的字符编码形式。Unicode标准由Unicode Consortium(www.unicode.org)发布。在ZIP文件中存储的UTF-8编码数据不应包含字节顺序标记(BOM)。
因此,在您的代码中,对于每个压缩文件,请首先检查通用位标志的第11位是否已设置。如果是,则可以确定该压缩文件的名称使用UTF-8进行编码。否则,编码是创建压缩文件时使用的任何编码方式。默认情况下,在Windows上为Cp437,但如果您在Windows上运行并处理在Linux上创建的zip文件,则我认为没有简单的确定所使用编码的方法。
不幸的是,
ZipEntry没有提供访问压缩文件的通用位标志字段的方法,因此需要以字节级别处理zip文件才能实现该功能。
要增加进一步复杂性,“编码”在这种情况下是指用于每个压缩文件名的编码,而不是zip文件本身的编码。一个压缩文件名可以使用UTF-8进行编码,另一个压缩文件名可以使用Cp437添加,等等。